ONNX Runtime Execution Providers
ONNX Runtime works with different hardware acceleration libraries through its extensible Execution Providers (EP) framework to optimally execute the ONNX models on the hardware platform. This interface enables flexibility for the AP application developer to deploy their ONNX models in different environments in the cloud and the edge and optimize the execution by taking advantage of the compute capabilities of the platform.
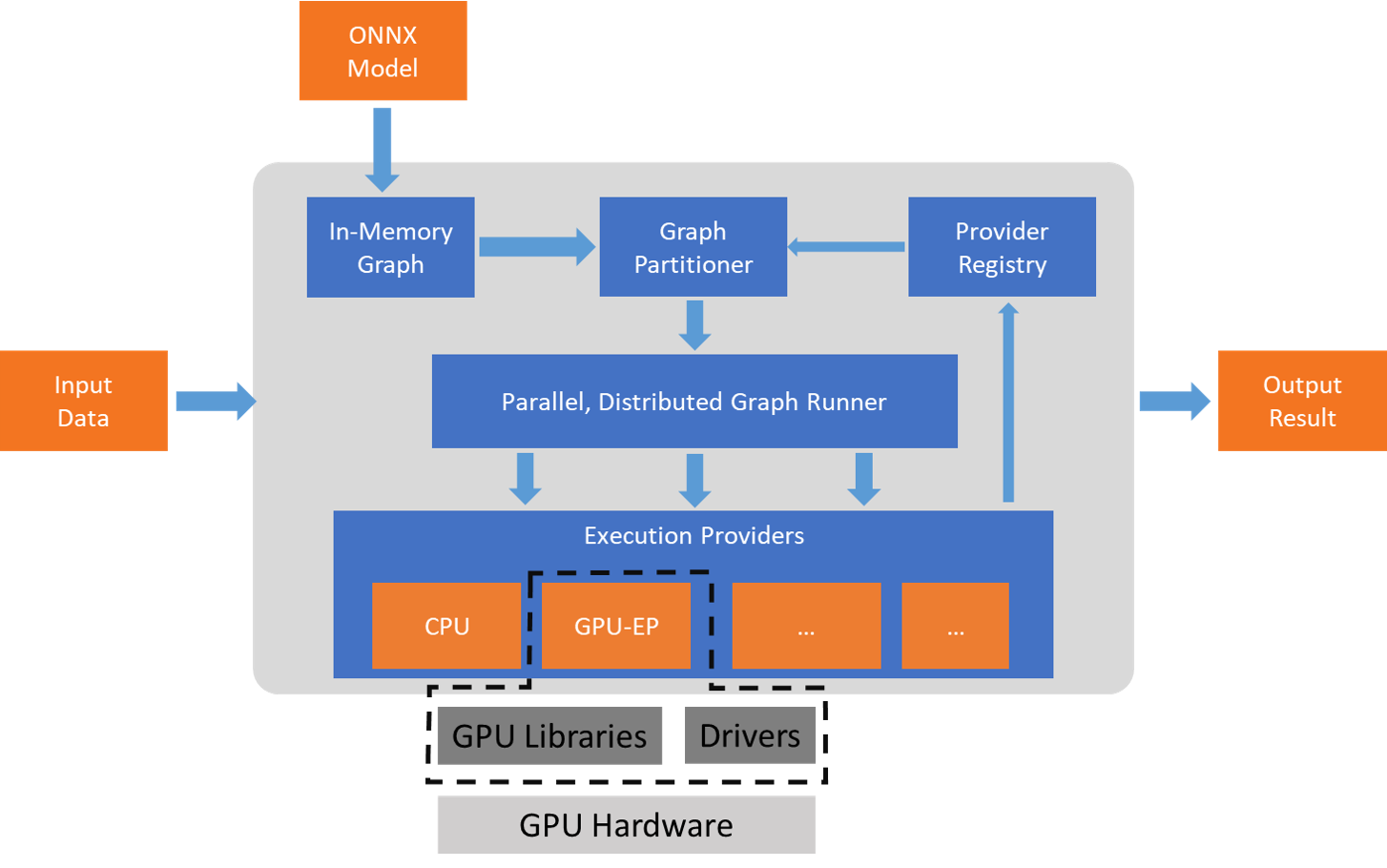
ONNX Runtime works with the execution provider(s) using the GetCapability() interface to allocate specific nodes or sub-graphs for execution by the EP library in supported hardware. The EP libraries that are pre-installed in the execution environment process and execute the ONNX sub-graph on the hardware. This architecture abstracts out the details of the hardware specific libraries that are essential to optimize the execution of deep neural networks across hardware platforms like CPU, GPU, FPGA or specialized NPUs.
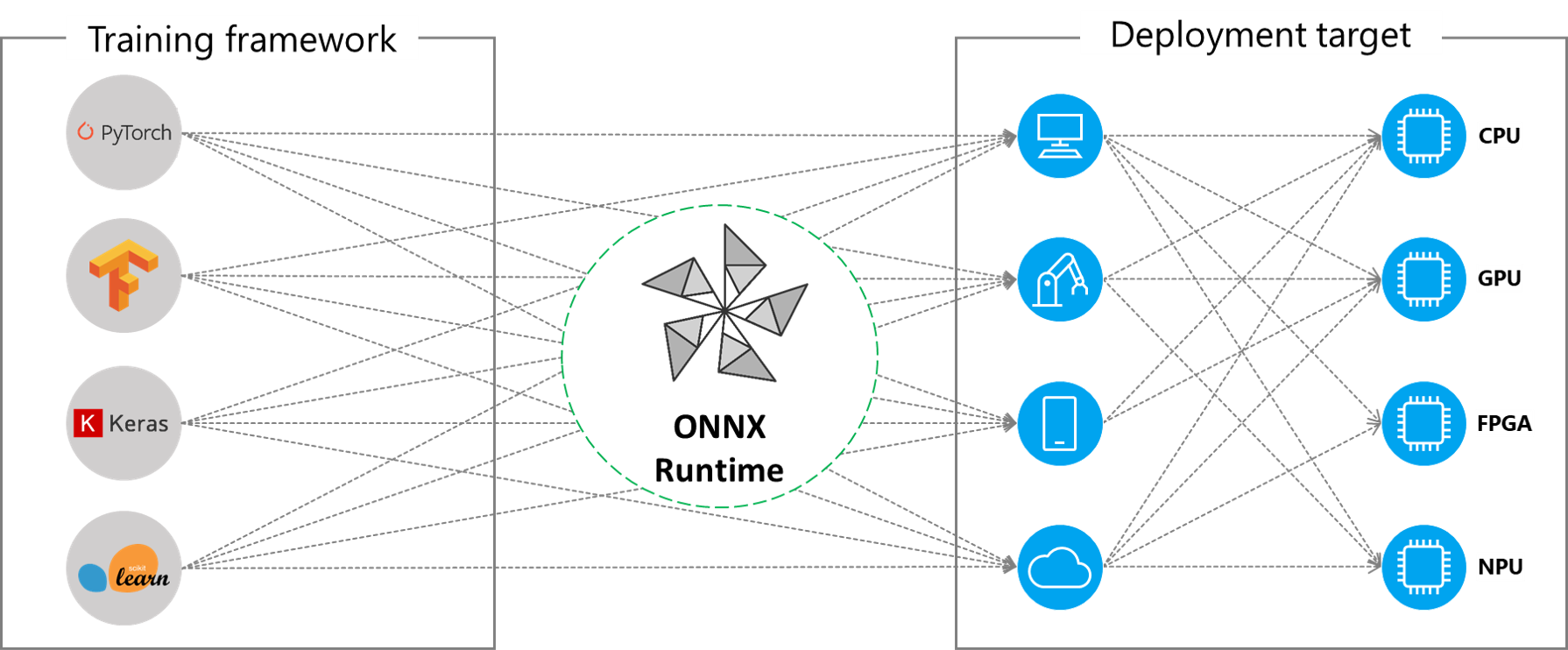
ONNX Runtime supports many different execution providers today. Some of the EPs are in production for live service, while others are released in preview to enable developers to develop and customize their application using the different options.
Summary of supported Execution Providers
| CPU | GPU | IoT/Edge/Mobile | Other |
|---|---|---|---|
| Default CPU | NVIDIA CUDA | Intel OpenVINO | Rockchip NPU (preview) |
| Intel DNNL | NVIDIA TensorRT | Arm Compute Library (preview) | Xilinx Vitis-AI (preview) |
| TVM (preview) | DirectML | Android Neural Networks API | Huawei CANN (preview) |
| Intel OpenVINO | AMD MIGraphX | Arm NN (preview) | AZURE (preview) |
| XNNPACK | Intel OpenVINO | CoreML (preview) | |
| AMD ROCm(deprecated) | Qualcomm QNN | XNNPACK |
Add an Execution Provider
Developers of specialized HW acceleration solutions can integrate with ONNX Runtime to execute ONNX models on their stack. To create an EP to interface with ONNX Runtime you must first identify a unique name for the EP. See: Add a new execution provider for detailed instructions.
Build ONNX Runtime package with EPs
The ONNX Runtime package can be built with any combination of the EPs along with the default CPU execution provider. Note that if multiple EPs are combined into the same ONNX Runtime package then all the dependent libraries must be present in the execution environment. The steps for producing the ONNX Runtime package with different EPs is documented here.
APIs for Execution Provider
The same ONNX Runtime API is used across all EPs. This provides the consistent interface for applications to run with different HW acceleration platforms. The APIs to set EP options are available across Python, C/C++/C#, Java and node.js.
Note we are updating our API support to get parity across all language binding and will update specifics here.
`get_providers`: Return list of registered execution providers.
`get_provider_options`: Return the registered execution providers' configurations.
`set_providers`: Register the given list of execution providers. The underlying session is re-created.
The list of providers is ordered by Priority. For example ['CUDAExecutionProvider', 'CPUExecutionProvider']
means execute a node using CUDAExecutionProvider if capable, otherwise execute using CPUExecutionProvider.
Use Execution Providers
import onnxruntime as rt
#define the priority order for the execution providers
# prefer CUDA Execution Provider over CPU Execution Provider
EP_list = ['CUDAExecutionProvider', 'CPUExecutionProvider']
# initialize the model.onnx
sess = rt.InferenceSession("model.onnx", providers=EP_list)
# get the outputs metadata as a list of :class:`onnxruntime.NodeArg`
output_name = sess.get_outputs()[0].name
# get the inputs metadata as a list of :class:`onnxruntime.NodeArg`
input_name = sess.get_inputs()[0].name
# inference run using image_data as the input to the model
detections = sess.run([output_name], {input_name: image_data})[0]
print("Output shape:", detections.shape)
# Process the image to mark the inference points
image = post.image_postprocess(original_image, input_size, detections)
image = Image.fromarray(image)
image.save("kite-with-objects.jpg")
# Update EP priority to only CPUExecutionProvider
sess.set_providers(['CPUExecutionProvider'])
cpu_detection = sess.run(...)
Table of contents
- NVIDIA - CUDA
- NVIDIA - TensorRT
- NVIDIA - TensorRT RTX
- Intel - OpenVINO™
- Intel - oneDNN
- Windows - DirectML
- Qualcomm - QNN
- Android - NNAPI
- Apple - CoreML
- XNNPACK
- AMD - ROCm
- AMD - MIGraphX
- AMD - Vitis AI
- Cloud - Azure
- Community-maintained
- Add a new provider
- EP Context Design
- Plugin Execution Provider Libraries