oneDNN Execution Provider
Formerly “DNNL”
Accelerate performance of ONNX Runtime using Intel® Math Kernel Library for Deep Neural Networks (Intel® DNNL) optimized primitives with the Intel oneDNN execution provider.
Intel® oneAPI Deep Neural Network Library is an open-source performance library for deep-learning applications. The library accelerates deep-learning applications and frameworks on Intel® architecture and Intel® Processor Graphics Architecture. Intel DNNL contains vectorized and threaded building blocks that you can use to implement deep neural networks (DNN) with C and C++ interfaces.
The oneDNN Execution Provider (EP) for ONNX Runtime is developed by a partnership between Intel and Microsoft.
Contents
Build
For build instructions, please see the BUILD page.
Usage
C/C++
The DNNLExecutionProvider execution provider needs to be registered with ONNX Runtime to enable in the inference session.
Ort::Env env = Ort::Env{ORT_LOGGING_LEVEL_ERROR, "Default"};
Ort::SessionOptions sf;
bool enable_cpu_mem_arena = true;
Ort::ThrowOnError(OrtSessionOptionsAppendExecutionProvider_Dnnl(sf, enable_cpu_mem_arena));
The C API details are here.
Python
When using the python wheel from the ONNX Runtime built with DNNL execution provider, it will be automatically prioritized over the CPU execution provider. Python APIs details are here.
Subgraph Optimization
DNNL uses blocked layout (example: nhwc with channels blocked by 16 – nChw16c) to take advantage of vector operations using AVX512. To get best performance, we avoid reorders (example. Nchw16c to nchw) and propagate blocked layout to next primitive.
Subgraph optimization achieves this in the following steps.
- Parses ONNX Runtime graph and creates an Internal Representation of subgraph..
- Subgraph Operator (DnnlFunKernel) iterates through DNNL nodes and creates a vector DNNL Kernels
- Compute Function of DnnlFunKernel iterates and binds data to DNNL primitives in the vector and submits vector for execution.
Subgraph (IR) Internal Representation
DnnlExecutionProvider::GetCapability() parses ONNX model graph and creates IR (Internal Representation) of subgraphs of DNNL operators. Each subgraph contains a vector DnnlNodes, inputs, outputs and attributes for all its DnnlNodes. There can be attributes of same name. So, we prefix attribute names with Node name and its index. Unique id for subgraph is set as an attribute.
DnnlNode has an index to its inputs and outputs and pointer to its parent nodes. DnnlNode directly reads blocked memory from its parent to avoid data reordering.

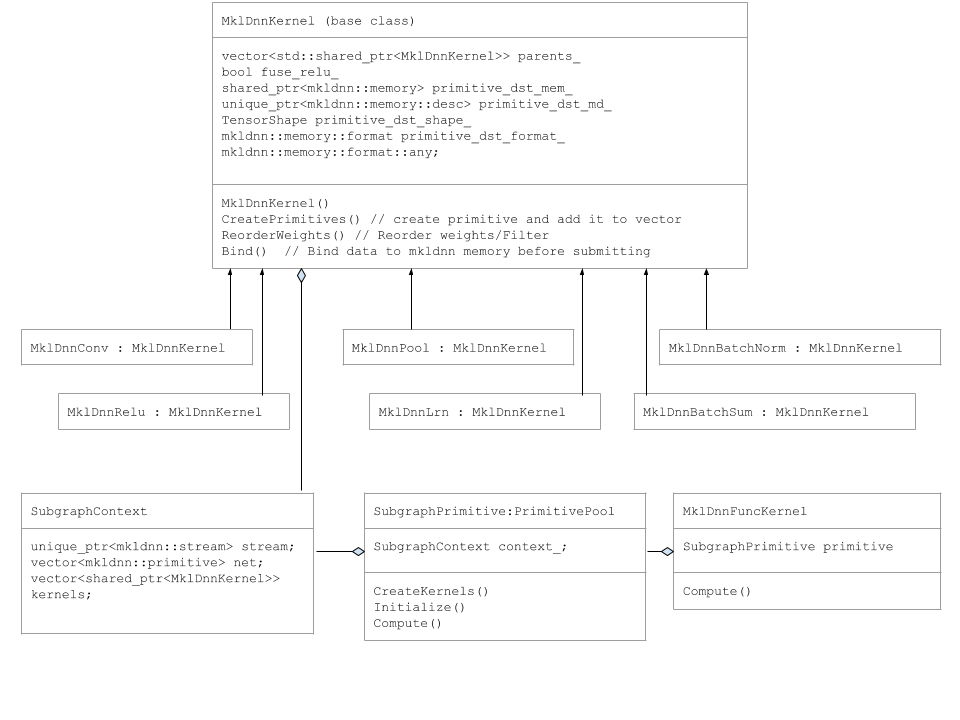
Subgraph Classes
Primitive like DnnlConv, DnnlPool, etc are derived from DnnlKernel base class.
The following UML diagram captures Subgraph classes.
Subgraph Execution
DnnlExecutionProvicer::Compute() function creates DnnlFuncKernel and call it’s Compute Function.
DnnlFuncKernel::Compute function creates SubgraphPrimitve pool and add the object to a map.
SubgraphPrimitve constructor calls the following member functions
SubgraphPrimitve::CreatePrimitives()
for (auto& mklnode : mklnodes) {
if (mklnode.name == "Conv") {
kernel.reset(new DnnlConv());
kernels.push_back(kernel);
} else if (mklnode.name == "BatchNormalization-Relu") {
kernel.reset(new DnnlBatchNorm());
context_.kernels.push_back(kernel);
} else if (mklnode.name == "MaxPool") {
kernel.reset(new DnnlPool());
context_.kernels.push_back(kernel);
}
.
.
.
In CreatePrimitives method, we iterate DnnlNodes and creates DnnlKernel objects and add DNNL primitive to a vector. It also reads attributes. This is done only once, at first iteration.
SubgraphPrimitve::Compute()
for (auto& kernel : kernels) {
kernel->Bind(input_tensors, output_tensors);
}
stream->submit(net);
In SubgraphPrimitve::Compute() method, we iterate thru Dnnl Kernels and bind input data. Then we submit the vector of Primitives to DNNL stream.
Support Coverage
Supported OS
- Ubuntu 16.04
- Windows 10
- Mac OS X
Supported backend
- CPU