How to develop a mobile application with ONNX Runtime
ONNX Runtime gives you a variety of options to add machine learning to your mobile application. This page outlines the flow through the development process. You can also check out the tutorials in this section:
- Build an objection detection application on iOS
- Build an image classification application on Android
- Build an super resolution application on iOS
- Build an super resolution application on Android
ONNX Runtime mobile application development flow
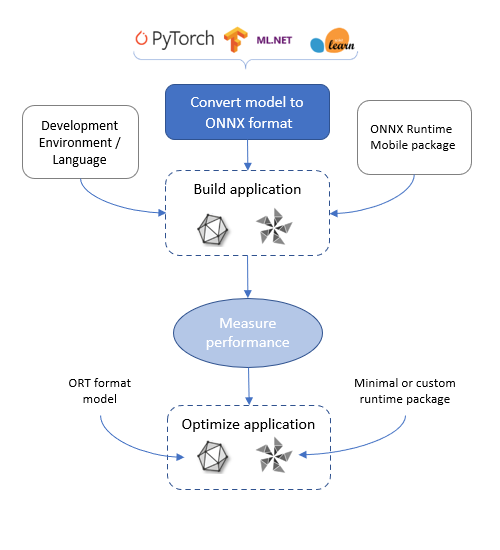
Obtain a model
The first step in developing your mobile machine learning application is to obtain a model.
You need to understand your mobile app’s scenario and get an ONNX model that is appropriate for that scenario. For example, does the app classify images, do object detection in a video stream, summarize or predict text, or do numerical prediction.
To run on ONNX Runtime mobile, the model is required to be in ONNX format. ONNX models can be obtained from the ONNX model zoo. If your model is not already in ONNX format, you can convert it to ONNX from PyTorch, TensorFlow and other formats using one of the converters.
Because the model is loaded and run on device, the model must fit on the device disk and be able to be loaded into the device’s memory.
Develop the application
Once you have a model, you can load and run it using the ONNX Runtime API.
Which language bindings and runtime package you use depends on your chosen development environment and the target(s) you are developing for.
- Android Java/C/C++: onnxruntime-android package
- iOS C/C++: onnxruntime-c package
- iOS Objective-C: onnxruntime-objc package
- Android and iOS C# in MAUI/Xamarin: Microsoft.ML.OnnxRuntime and Microsoft.ML.OnnxRuntime.Managed
See the install guide for package specific instructions.
The above packages all contain the full ONNX Runtime feature and operator set and support for the ONNX format. We recommend you start with these to develop your application. Further optimizations may be required. These are detailed below.
You have a choice of hardware accelerators to use in your app, depending on the target platform:
- All targets have support for CPU and this is the default
- Applications that run on Android also have support for NNAPI and XNNPACK
- Applications that run on iOS also have support for CoreML and XNNPACK
Accelerators are called Execution Providers in ONNX Runtime.
If the model is quantized, start with the CPU Execution Provider. If the model is not quantized start with XNNPACK. These are the simplest and most consistent as everything is running on CPU.
If CPU/XNNPACK do not meet the application’s performance results, then try NNAPI/CoreML. Performance with these execution providers is device and model specific. If the model is broken into multiple partitions due to the model using operators that the execution provider doesn’t support (e.g., due to older NNAPI versions), performance may degrade.
Specific execution providers are configured in the SessionOptions, when the ONNXRuntime session is created and the model is loaded. For more detail, see your language API docs.
Measure the application’s performance
Measure the application’s performance against the requirements of your target platform. This includes:
- application binary size
- model size
- application latency
- power consumption
If the application does not meet its requirements, there are optimizations that can be applied.
Optimize your application
Reduce model size
One method of reducing model size is to quantize the model. This reduces an original model with 32-bit weights by approximately a factor of 4, as the weights are reduced to 8-bit. See the ONNX Runtime quantization guide for instructions on how to do this.
Another way of reducing the model size is to find a new model with the same inputs, outputs and architecture that has already been optimized for mobile. For example: MobileNet and MobileBert.
Reduce application binary size
To reduce the ONNX Runtime binary size, you can build a custom runtime based on your model(s).
Refer to the process to build a custom runtime.
One of the outputs of the ORT format conversion is a build configuration file, containing a list of operators from your model(s) and their types. You can use this configuration file as input to the custom runtime binary build.
To give an idea of the binary size difference between the pre-built package and a custom build:
| File | 1.18.0 pre-built package size (bytes) | 1.18.0 custom build size (bytes) |
|---|---|---|
| AAR | 24415212 | 7532309 |
jni/arm64-v8a/libonnxruntime.so, uncompressed | 16276832 | 3962832 |
jni/x86_64/libonnxruntime.so, uncompressed | 18222208 | 4240864 |
This custom build supports the operators needed to run a ResNet50 model. It requires the use of ORT format models (as it was built with --minimal_build=extended). It has support for the NNAPI and XNNPACK execution providers.