ONNX Runtime for Training
ONNX Runtime can be used to accelerate both large model training and on-device training.
Large Model Training
ORTModule accelerates training of large transformer based PyTorch models. The training time and training cost is reduced with a few lines of code change. It is built on top of highly successful and proven technologies of ONNX Runtime and ONNX format. It is composable with technologies like DeepSpeed and accelerates pre-training and finetuning for state of the art LLMs. It is integrated in the Hugging Face Optimum library which provides an ORTTrainer API to use ONNX Runtime as the backend for training acceleration.
- model = build_model() # User's PyTorch model
+ model = ORTModule(build_model())Get started with large model training →
Benefits
Faster training
Optimized kernels and memory optimizations provides >1.5X speed up in training time.
Flexible & extensible hardware support
The same model and API works with NVIDIA and AMD GPUs, and the extensible "execution provider" architecture allow you to plug-in custom operators, optimizer and hardware accelerators.
Part of the PyTorch ecosystem
ONNX Runtime Training is available via the torch-ort package as part of the Azure Container for PyTorch (ACPT) and seamlessly integrates with existing training pipelines for PyTorch models.
Works with Azure AI curated models
ORT Training is turned on for curated models in the Azure AI | Machine Learning Studio model catalog.
Can be used to accelerate popular models like Llama-2-7b
ORT Training can be used to accelerate Hugging Face models like Llama-2-7b through these scripts.
Improved Foundation Model Performance with ORT Training
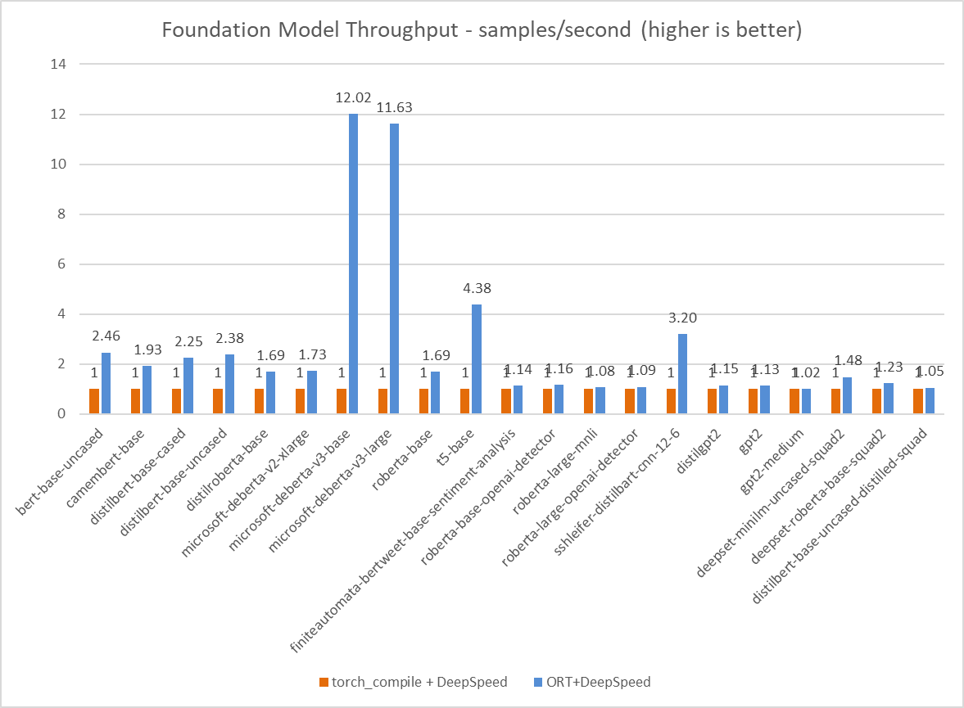
On-Device Training
On-Device Training refers to the process of training a model on an edge device, such as mobile phones, embedded devices, gaming consoles, web browsers, etc. This is in contrast to training a model on a server or a cloud. On-Device Training extends the Inference ecosystem to leverage data on the device for providing customized user experiences on the edge. Once the model is trained on the device, it can be used to get an Inference model for deployment, update global weights for federated learning or create a checkpoint for future use. It also preserves user privacy by training on the device.
Get started with on-device training →
Benefits
Memory and performance efficiency
for lower resource consumption on device
Simple APIs and multiple language bindings
make it easy to scale across multiple platform targets
Improves data privacy & security
especially when working with sensitive data that cannot be shared with a server or a cloud
Same solution runs cross-platform
on cloud, desktop, edge, and mobile
Use Cases
Personalization tasks where the model needs to be trained on the user's data
Examples:- Image / Audio classification
- Text Prediction
Federated learning tasks where the model is locally trained on data distributed across multiple devices to build a more robust aggregated global model
Examples:- Medical research
- Autonomous vehicles
- Robotics