ONNX Runtime 1.17: CUDA 12 support, Phi-2 optimizations, WebGPU, and more!
By:
Sophie Schoenmeyer, Parinita Rahi, Kshama Pawar, Caroline Zhu, Chad Pralle, Emma Ning, Natalie Kershaw, Jian Chen28TH FEBRUARY, 2024
Recently, we released ONNX Runtime 1.17, which includes a host of new features to further streamline the process of inferencing and training machine learning models across various platforms faster than ever. The release includes improvements to some of our existing features, along with exciting new features like Phi-2 optimizations, training a model in-browser with on-device training, ONNX Runtime Web with WebGPU, and more.
For a complete list of new features, along with various assets, check out the 1.17 release and our recent 1.17.1 patch release on GitHub.
Model Optimization
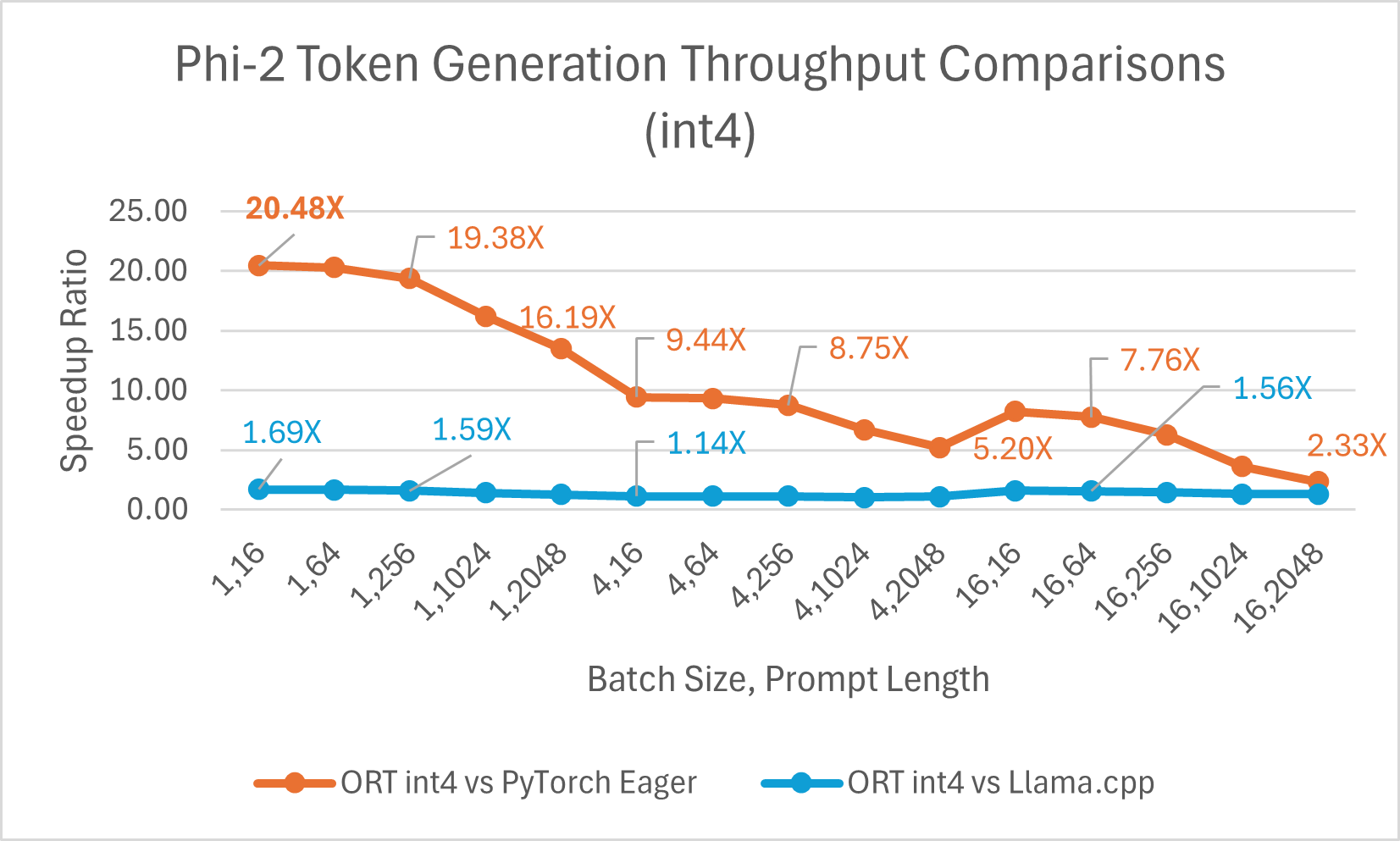
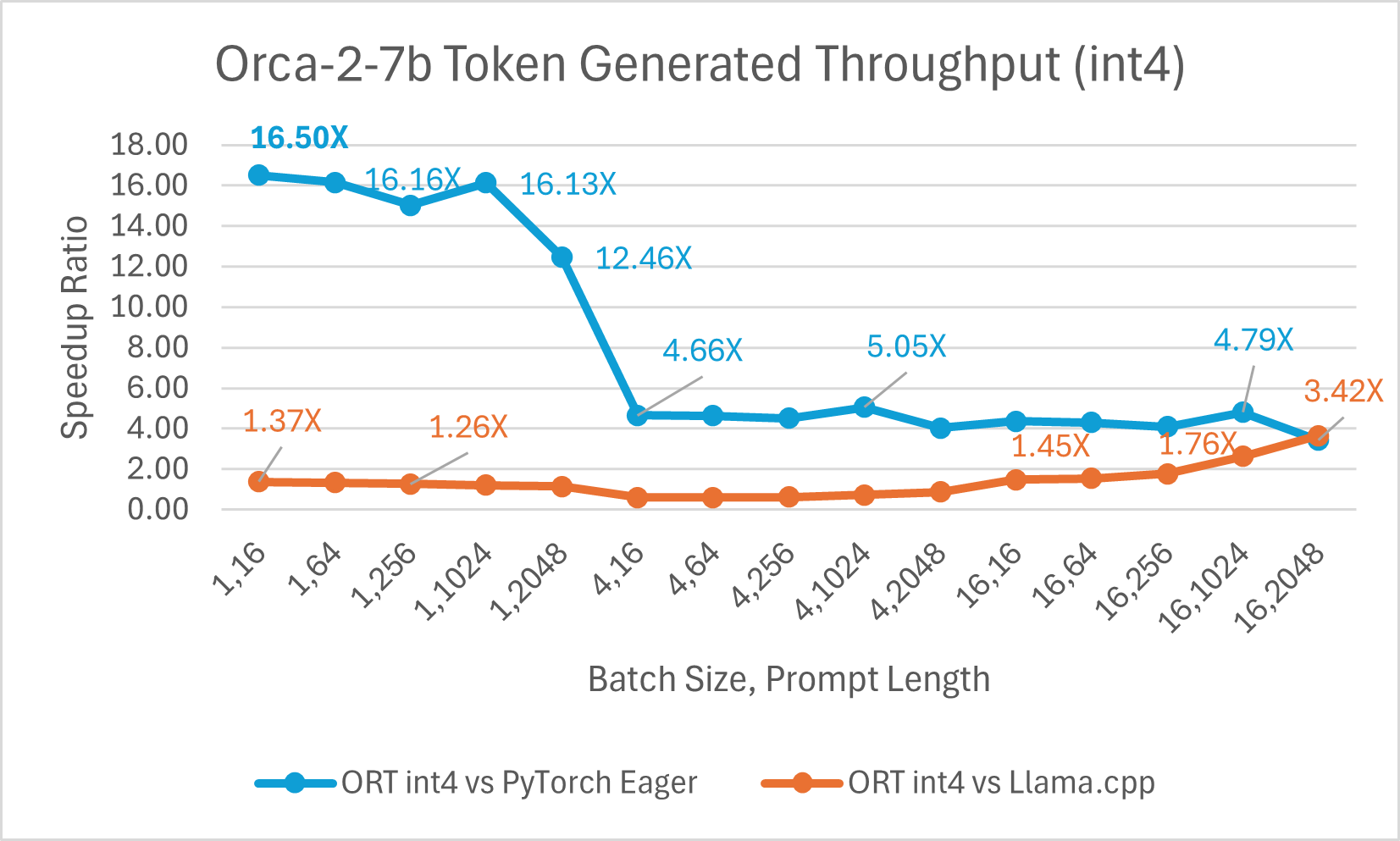
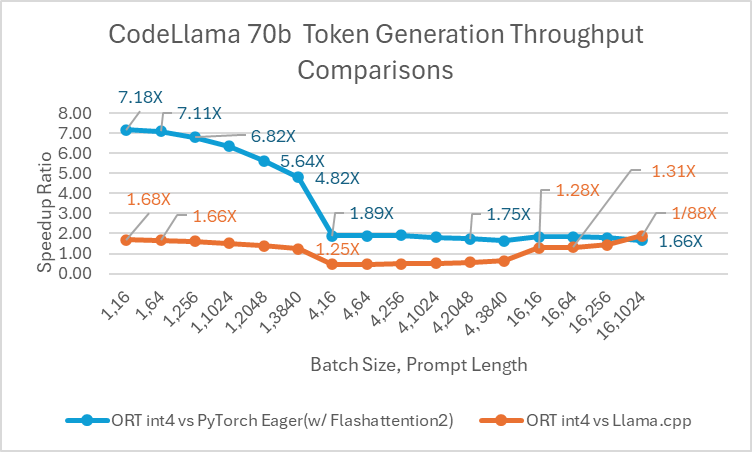
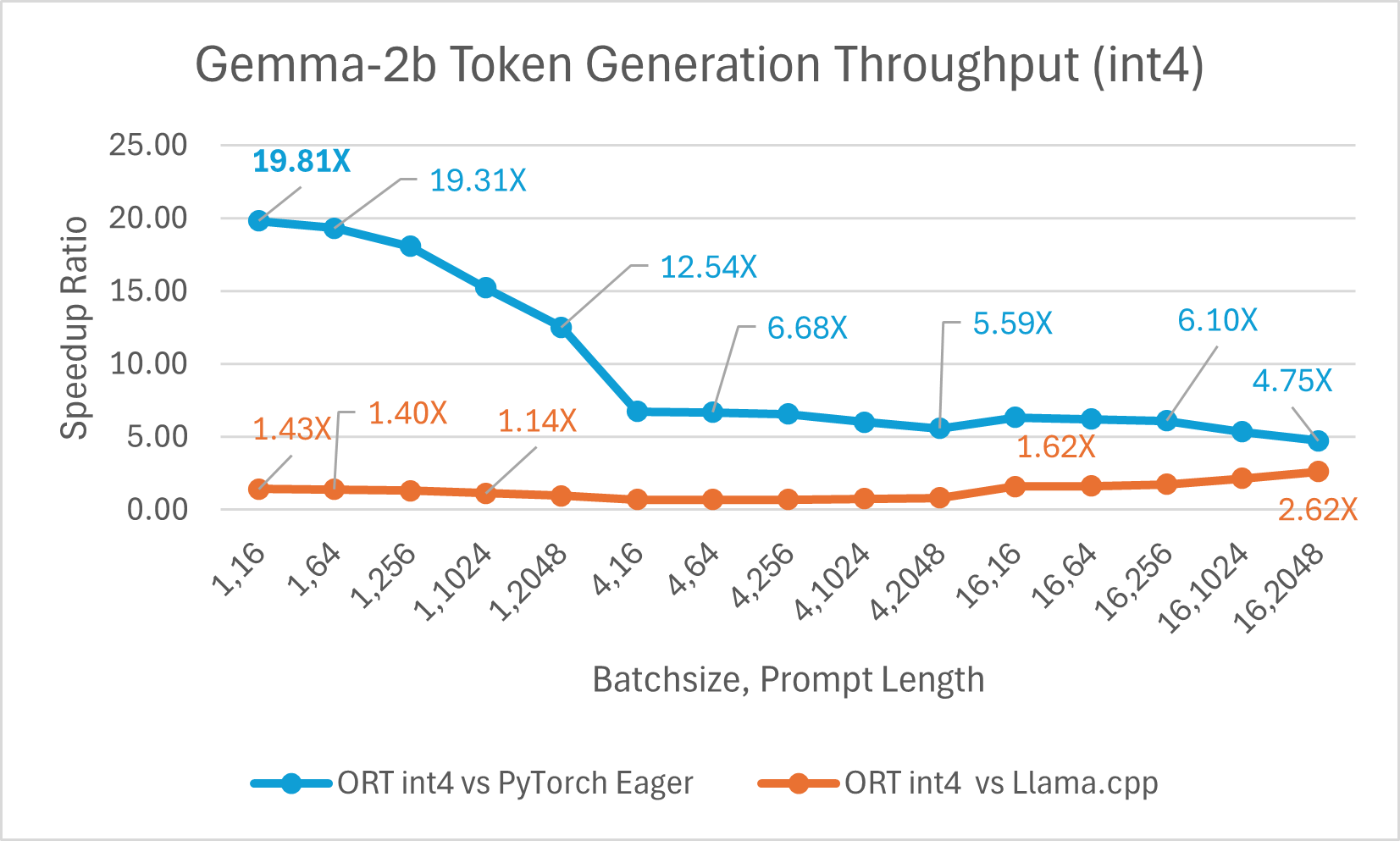
The ONNX Runtime (ORT) 1.17 release provides improved inference performance for several models, such as Phi-2, Mistral, CodeLlama, Google’s Gemma, SDXL-Turbo, and more by using state-of-the-art fusion and kernel optimizations and including support for float16 and int4 quantization. The specific ORT optimizations added in this release are Attention, Multi-Head Attention, Grouped-Query Attention, and Rotary Embedding ORT kernel changes. ORT outperforms other frameworks like PyTorch, DeepSpeed, and Llama.cpp in terms of prompt and token generation throughput, with speedups as high as 20x faster. In particular, we observe performance improvements as high as 20.5x for Phi-2, 16.0x for Orca-2, and 19.8x for Gemma (see linked blog below for additional details for each model). ONNX Runtime with int4 quantization performs best with batch size 1 due to a special GemV kernel implementation. Overall, ONNX Runtime demonstrates significant performance gains across several batch sizes and prompt lengths.
ONNX Runtime also shows significant benefits for training LLMs, and these gains typically increase with batch size. For example, ORT is 1.2x faster than PyTorch Eager mode and 1.5x faster than torch.compile for Phi-2 with LoRA on 2 A100 GPUs. ORT also shows benefits for other LLMs, like Llama, Mistral, and Orca-2, with combinations of LoRA or QLoRA.
To read more about improving generative AI model performance with ONNX Runtime 1.17, check out our recent post on the ONNX Runtime blog: Accelerating Phi-2, CodeLlama, Gemma and other Gen AI models with ONNX Runtime.
In-Browser Training
On-device training allows you to improve the user experience for developer applications using device data. It supports scenarios like federated learning, which trains a global model using data on the device. With the 1.17 release, ORT will now enable training machine learning models in the browser using on-device training.
To learn more about training a model in browser with on-device training, check out this recent post on the Microsoft Open Source Blog: On-Device Training: Training a model in browser.
DirectML NPU Support
With the release of DirectML 1.13.1 and ONNX Runtime 1.17, developer preview support for neural processing unit (NPU) acceleration is now available in DirectML, the machine learning platform API for Windows. This developer preview enables support for a subset of models on new Windows 11 devices with Intel® Core™ Ultra processors with Intel® AI boost.
To learn more about NPU support in DirectML, check out this recent post on the Windows Developer Blog: Introducing Neural Processor Unit (NPU) support in DirectML (developer preview).
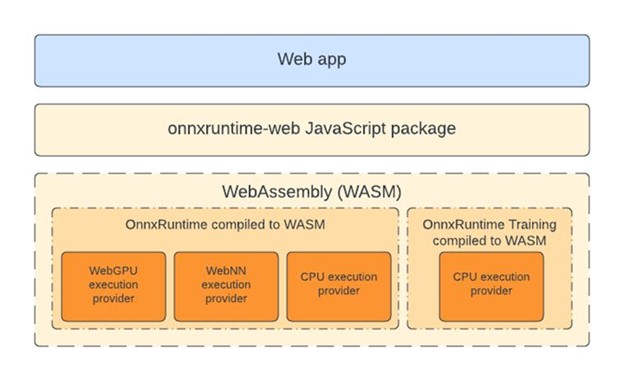
WebGPU with ONNX Runtime Web
WebGPU enables web developers to harness GPU hardware for high-performance computations. The ONNX Runtime 1.17 release introduces the official launch of the WebGPU execution provider in ONNX Runtime Web, allowing sophisticated models to run entirely and efficiently within the browser (see the list of WebGPU browser compatibility). This advancement, demonstrated by the effective execution of models such as SD-Turbo, unlocks new possibilities in scenarios where CPU-based in-browser machine learning faces challenges in meeting performance standards.
To learn more about how ONNX Runtime Web further accelerates in-browser machine learning with WebGPU, check out our recent post on the Microsoft Open Source Blog: ONNX Runtime Web unleashes generative AI in the browser using WebGPU.
YOLOv8 Pose Estimation Scenario with ONNX Runtime Mobile
This release adds support for running the YOLOv8 model for pose estimation. Pose estimation involves processing the objects detected in an image and identifying the position and orientation of people in the image. The core YOLOv8 model returns a set of key points, representing specific parts of the detected person’s body, such as joints and other distinctive features. Including the pre- and post-processing in the ONNX model allows developers to supply an input image directly, either in common image formats or raw RGB values, and output the image with bounding boxes and key points.
To learn more about how to build and run ONNX models on mobile with built-in pre and post processing for object detection and pose estimation, check out our recent tutorial in the ONNX Runtime documentation: Object detection and pose estimation with YOLOv8.

CUDA 12 Packages
As part of the 1.17 release, ONNX Runtime now ensures compatibility across multiple versions of Nvidia’s CUDA execution provider by introducing CUDA 12 packages for Python and NuGet. With this more flexible methodology, users will now have access to both CUDA 11 and CUDA 12, allowing for more seamless integration of cutting-edge hardware acceleration technologies.
To install CUDA 12 for ONNX Runtime GPU, refer to the instructions in the ONNX Runtime docs: Install ONNX Runtime GPU (CUDA 12.X).