Accelerating Phi-2, CodeLlama, Gemma and other Gen AI models with ONNX Runtime
By:
Parinita Rahi, Sunghoon Choi, Yufeng Li, Kshama Pawar, Ashwini Khade, Ye Wang26TH FEBRUARY, 2024
In a fast-moving landscape where speed and efficiency are paramount, ONNX Runtime (ORT) allows users to easily integrate the power of generative AI models into their apps and services with improved optimizations that yield faster inferencing speeds and effectively lowers costs. These include state-of-the-art fusion and kernel optimizations to help improve model performance. The recent ONNX Runtime 1.17 release improves inference performance of several Gen AI models including Phi-2, Mistral, CodeLlama, Orca-2 and more. ONNX Runtime is a complete solution for small language models (SLMs) from training to inference, showing significant speedups compared to other frameworks. With support for float32, float16, and int4, ONNX Runtime’s inference enhancements provide maximum flexibility and performance.
In this blog, we will cover significant optimization speed up for both training and inference for the latest GenAI models like Phi-2, Mistral, CodeLlama, SD-Turbo, SDXL-Turbo, Llama2, and Orca-2. For these model architectures, ONNX Runtime significantly improves performance across a spectrum of batch sizes and prompt lengths when compared against other frameworks like PyTorch, and Llama.cpp. These optimizations using ONNX Runtime are now also available using Olive.
Quick Links
Phi-2
Phi-2 is a 2.7 billion parameter transformer model developed by Microsoft. It is an SLM that exhibits excellent reasoning and language comprehension skills. With its small size, Phi-2 is a great platform for researchers, who can explore various aspects such as mechanistic interpretability, safety improvements, and fine-tuning experiments on different tasks.
ONNX Runtime 1.17 introduces kernels changes that support the Phi-2 model, including optimizations for Attention, Multi-Head Attention, Grouped-Query Attention, and RotaryEmbedding for Phi-2. Specifically, support has been added for the following:
- causal mask in the Multi-Head Attention CPU kernel
- rotary_embedding_dim in the Attention and Rotary Embedding kernels
- bfloat16 in the Grouped-Query Attention kernel
TorchDynamo-based ONNX export for Phi-2 is supported, and the optimization script is built on top.
For Phi-2 inference, ORT with float16 and int4 quantization performs better than ORT with float32, PyTorch, and Llama.cpp for all prompt lengths.
Inferencing
ORT gains with float16
Optimized CUDA performance for prompt throughput (i.e., the rate at which the model processes and generates responses based on input prompts) is up to 7.39x faster than PyTorch Compile. We also observe ONNX Runtime is significantly faster for larger batch size and prompt lengths compared to Llama.cpp. For example, it is up to 13.08x faster for batch size =16, prompt length =2048.
Token generation throughput is the average throughput of the first 256 tokens generated. ONNX Runtime with float16 is on average 6.6x faster than torch.compile and as high as 18.55x faster. It also performs up to 1.64x faster than Llama.cpp.
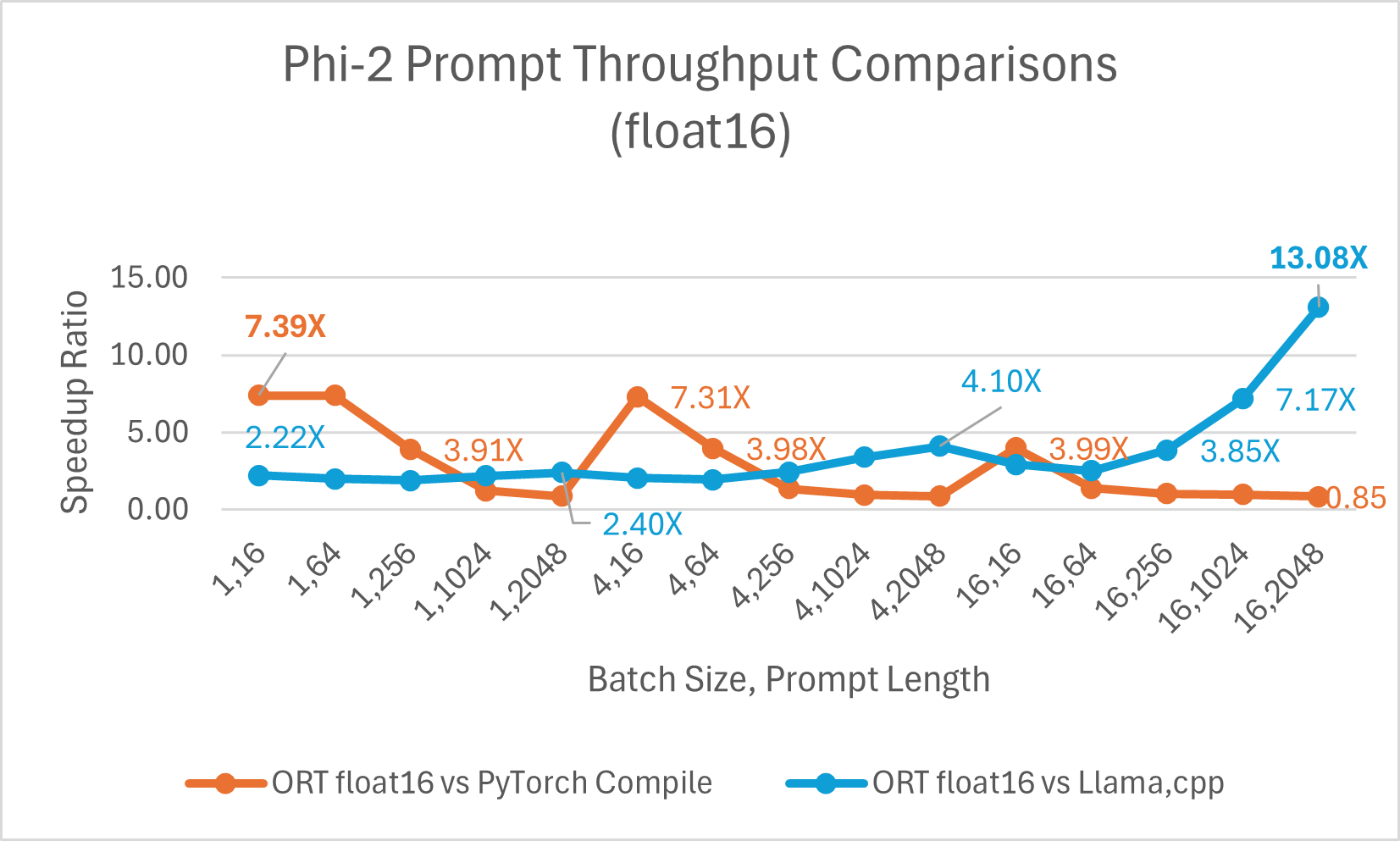
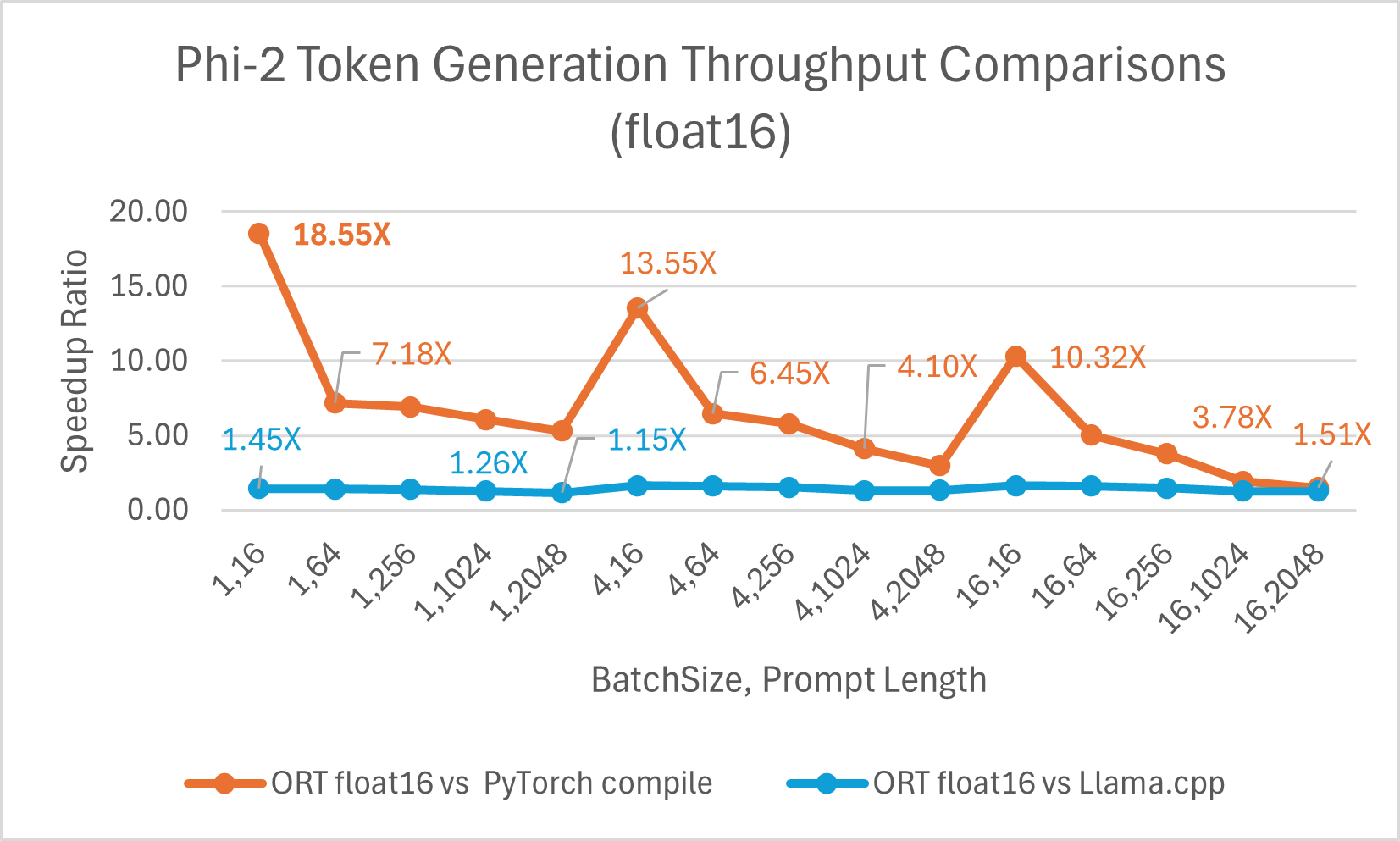
ORT gains with int4
ORT provides support for int4 quantization. ORT with int4 quantization can provide up to 20.48x improved performance compared to PyTorch. It is 3.9x better than Llama.cpp on average and up to 13.42x faster for large sequence lengths. ONNX Runtime with int4 quantization typically performs best with batch size 1 due to a special kernel for GemV.
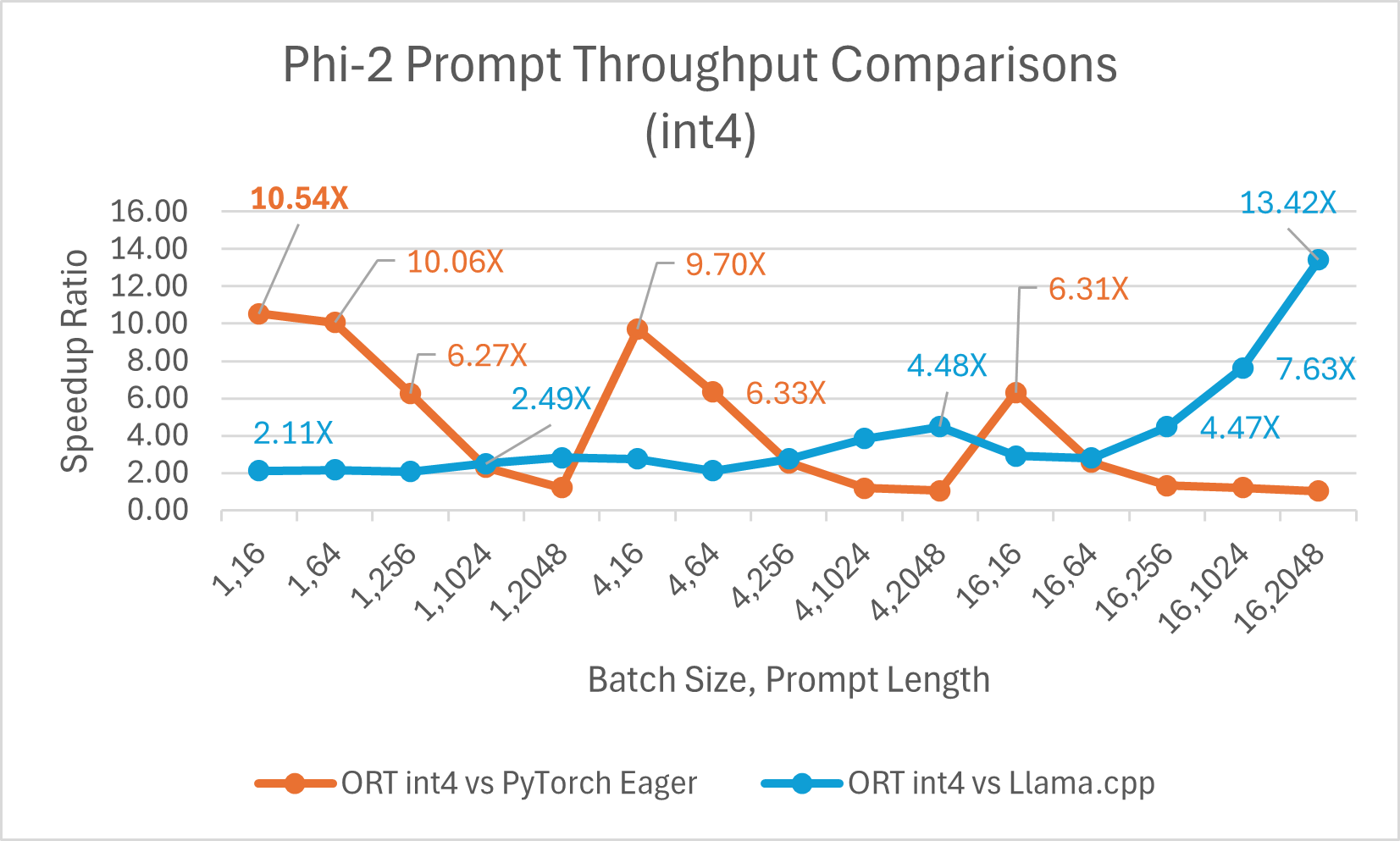
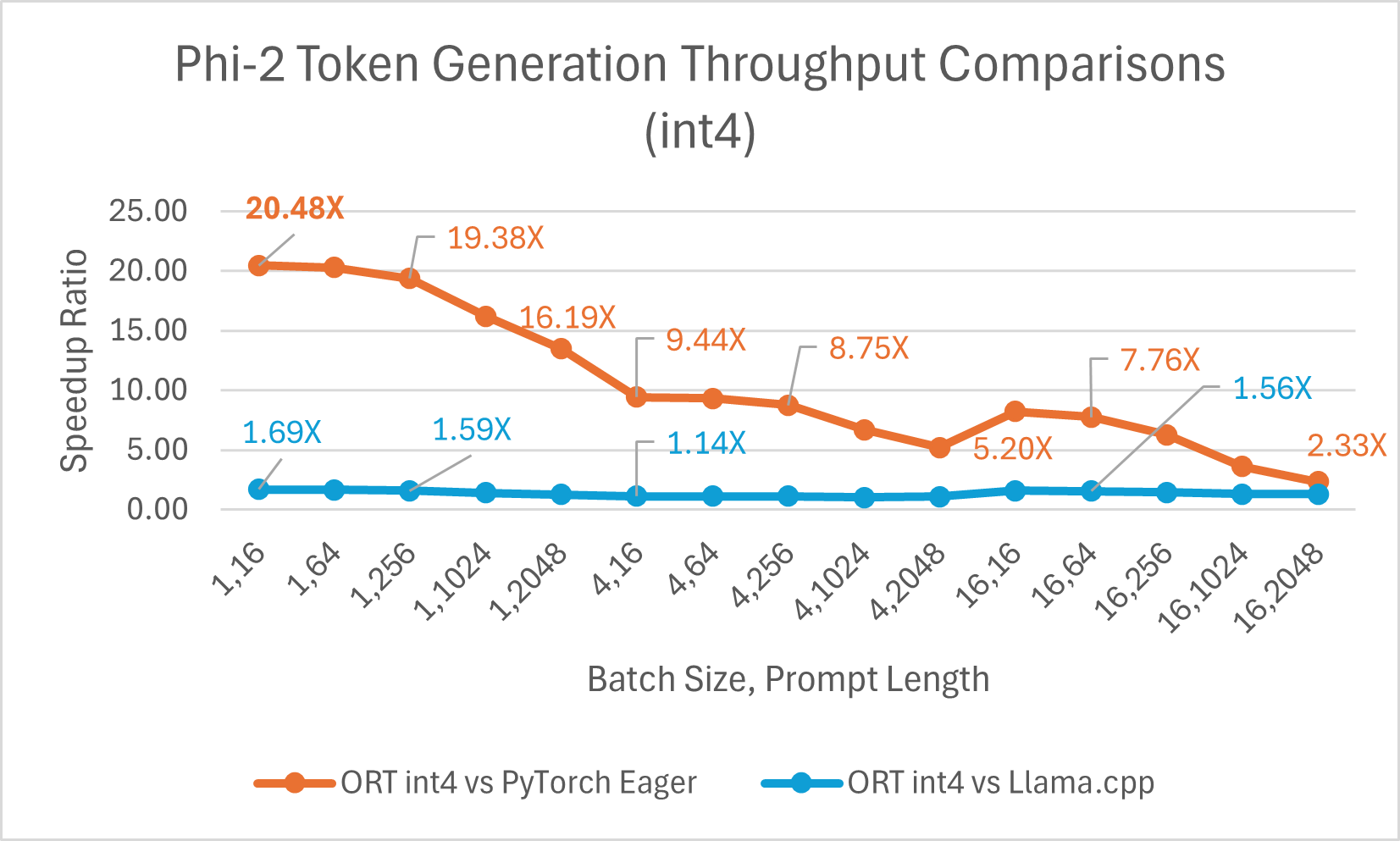
- Phi-2 benchmarks is done on 1 A100 GPU (SKU: Standard_ND96amsr_A100_v4).Packages: torch: 2.3.0. dev20231221+cu121; pytorch-triton: 2.2.0+e28a256d71;ort-nightly-gpu: 1.17.0.dev20240118001;deepspeed: 0.12
- Batch is a set of input sentences of varying lengths; prompt length refers to the size or length of the input text.
Here is an example of Phi-2 optimizations with Olive, which utilizes the ONNX Runtime optimizations highlighted in this blog using easy-to-use hardware-aware model optimization tool, Olive.
Training
In addition to inference, ONNX Runtime also provides training speedup for Phi-2 and other LLMs. ORT training is part of the PyTorch Ecosystem and is available via the torch-ort python package as part of the Azure Container for PyTorch (ACPT). It provides flexible and extensible hardware support, where the same model and APIs works with both NVIDIA and AMD GPUs. ORT accelerates training through optimized kernels and memory optimizations which show significant gains in reducing end-to-end training time for large model training. This involves changing a few lines of code in the model to wrap it with the ORTModule API. It is also composable with popular acceleration libraries like DeepSpeed and Megatron for faster and more efficient training.
Open AI’s Triton is a domain specific language and compiler to write highly efficient custom deep learning primitives. ORT supports Open AI Triton integration (ORT+Triton), where all element wise operators are converted to Triton ops and ORT creates custom fused kernels in Triton.
ORT also performs sparsity optimization to assess input data sparsity and perform graph optimizations leveraging this sparsity. This reduces the compute FLOP requirements and increases performance.
Low-Rank Adapters (LoRA) based fine-tuning makes training more efficient by training only a small number of additional parameters (the adapters) while freezing the original model’s weights. These adapters adapt the model to specific tasks. Quantization and LoRA (QLoRA) combines quantization with LoRA where the weights are represented using fewer bits, while preserving the performance and quality of the model. ONNX Runtime training composes with both LoRA and QLoRA to provide gains in memory efficiency and training time acceleration for LLMs. LoRA and QLoRA techniques enable very large models like LLMs to fit in the GPU memory to efficiently complete training.
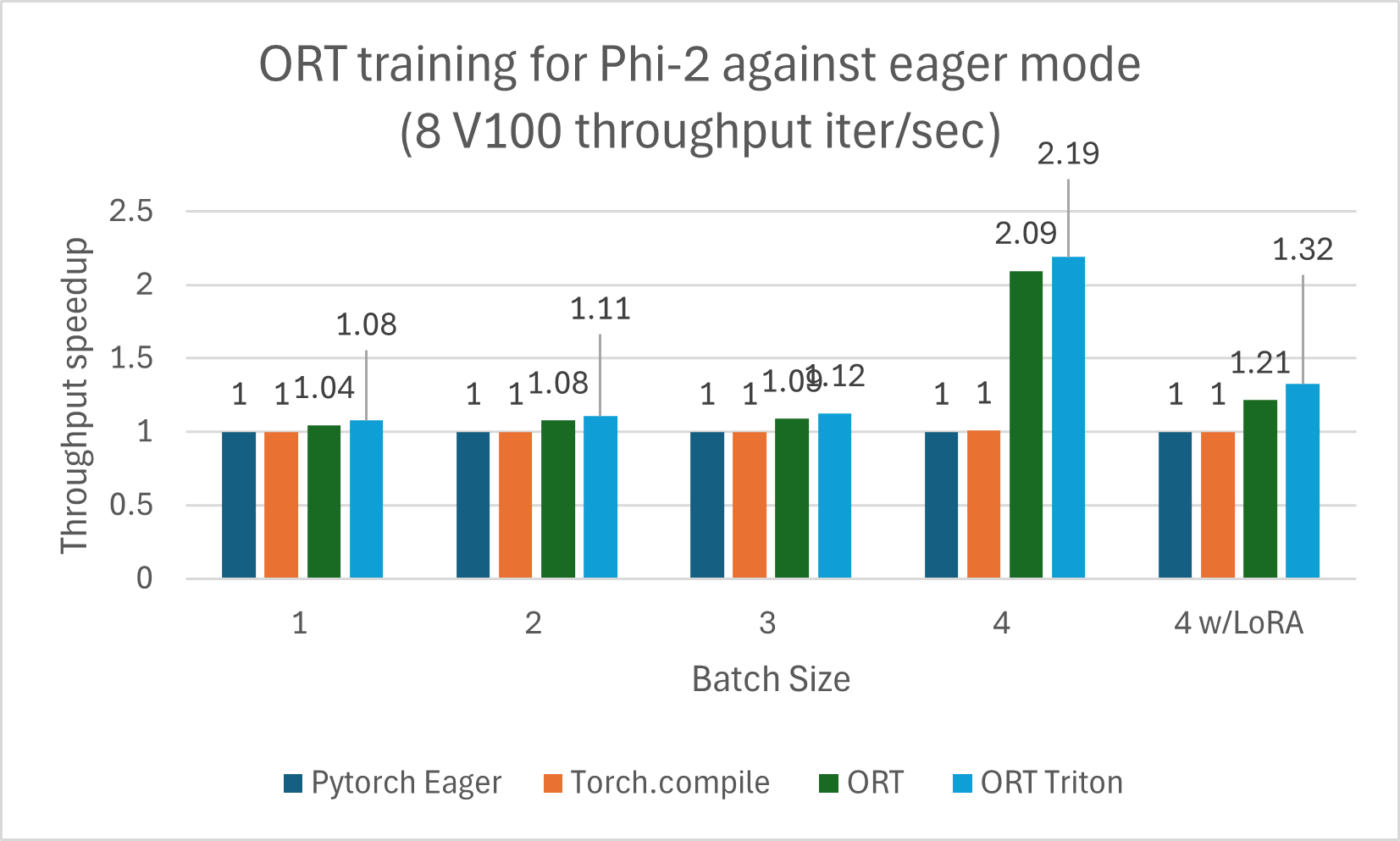
The Phi-2 model trained using ORT shows performance gains against PyTorch Eager mode and torch.compile. Phi-2 was trained using a mixture of synthetic and web datasets. We measured gains against ORT and the ORT+Triton mode, and gains increased with larger batch sizes. The model was trained using DeepSpeed Stage-2 for 5 epochs, with increasing batch sizes on the wikitext dataset. The gains are summarized in the charts below for V100 and A100.
The training benchmarks were run on 8 V100 and measured throughput in iterations/second (higher is better):
The training benchmarks below were run on 2 A100 and measured throughput in iterations/second (higher is better):
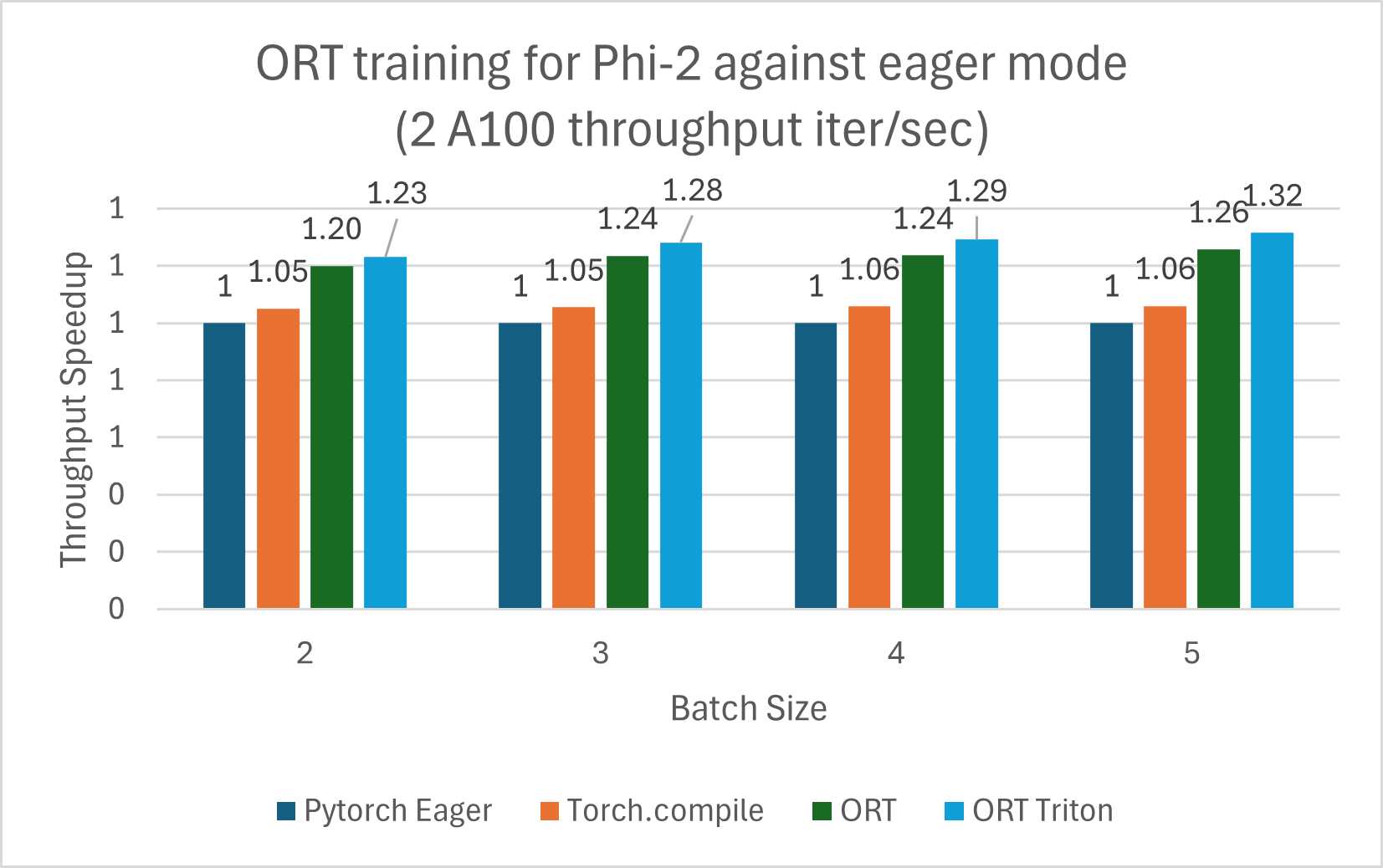 Note: PyTorch Stable 2.2.0 and ONNXRuntime Training: Stable 1.17.0 versions were used.
Note: PyTorch Stable 2.2.0 and ONNXRuntime Training: Stable 1.17.0 versions were used. Mistral
Inferencing
Mistral7B is a pretrained generative text LLM with 7 billion parameters. ONNX Runtime improves inference performance significantly for Mistral with both float16 and int4 models. With float16, ONNX Runtime is as high as 9.46x compared to Llama.cpp. Token generation throughput significantly improves with int4 quantization for batch size 1 and is up to 18.25x faster than PyTorch Eager.
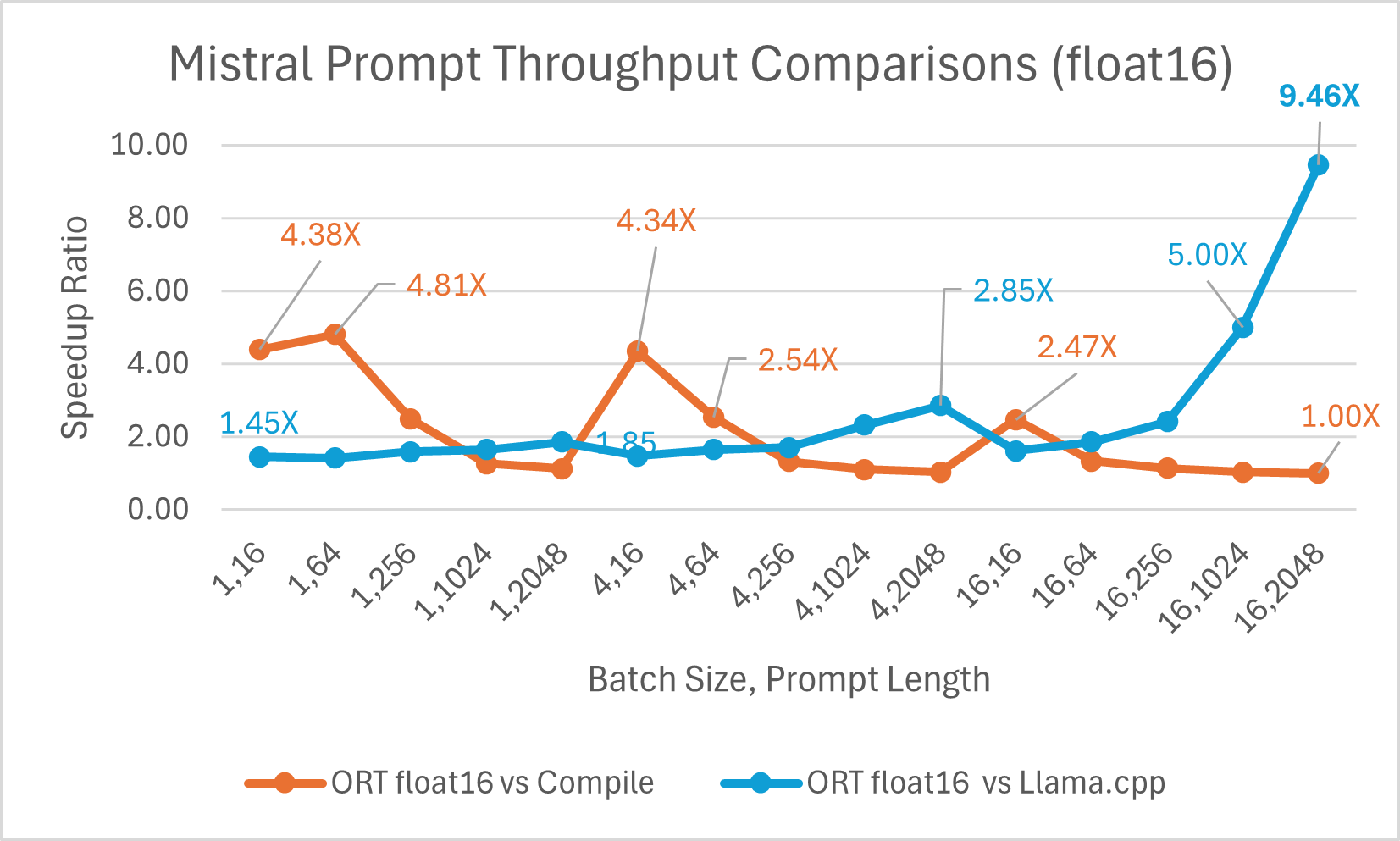
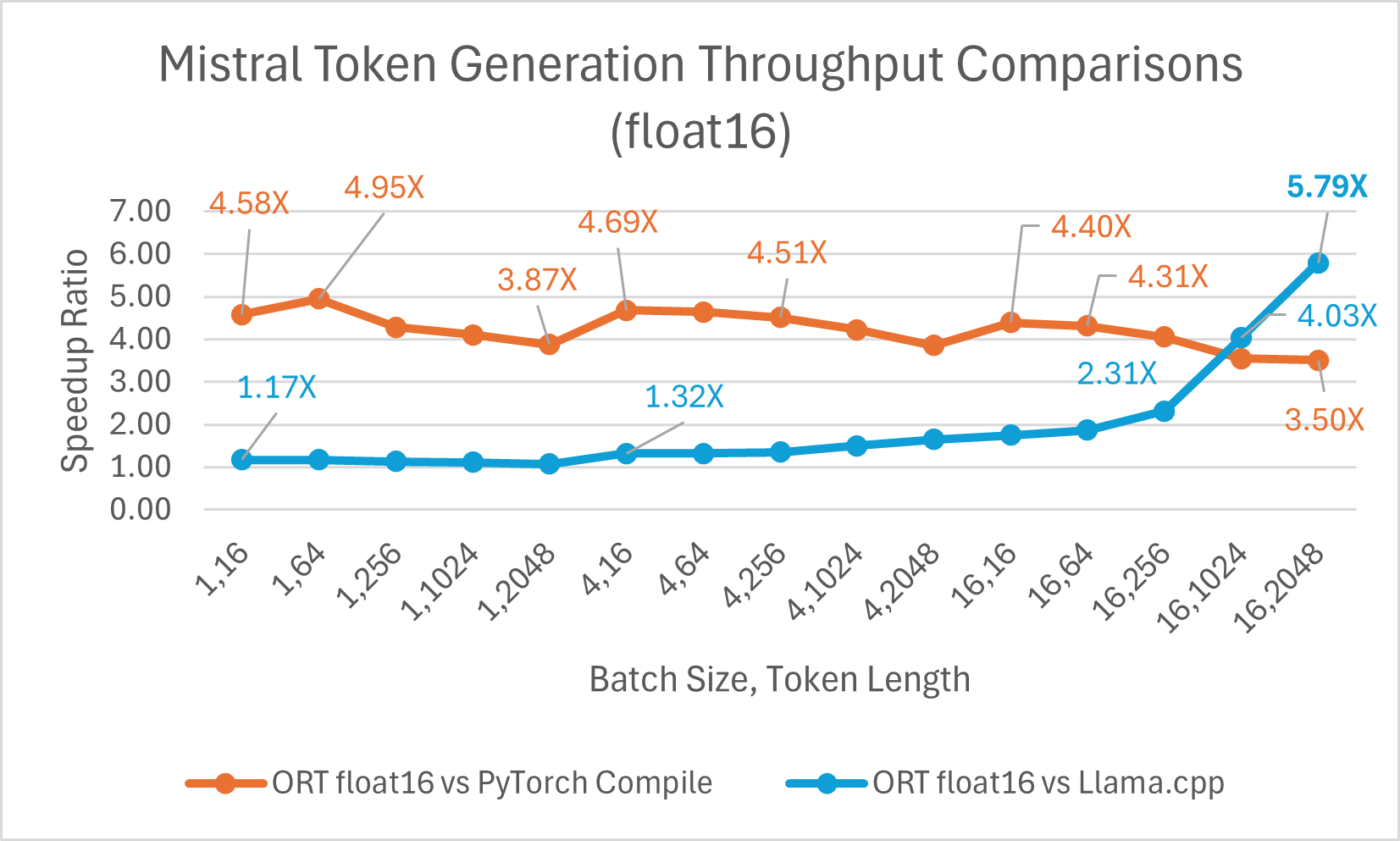
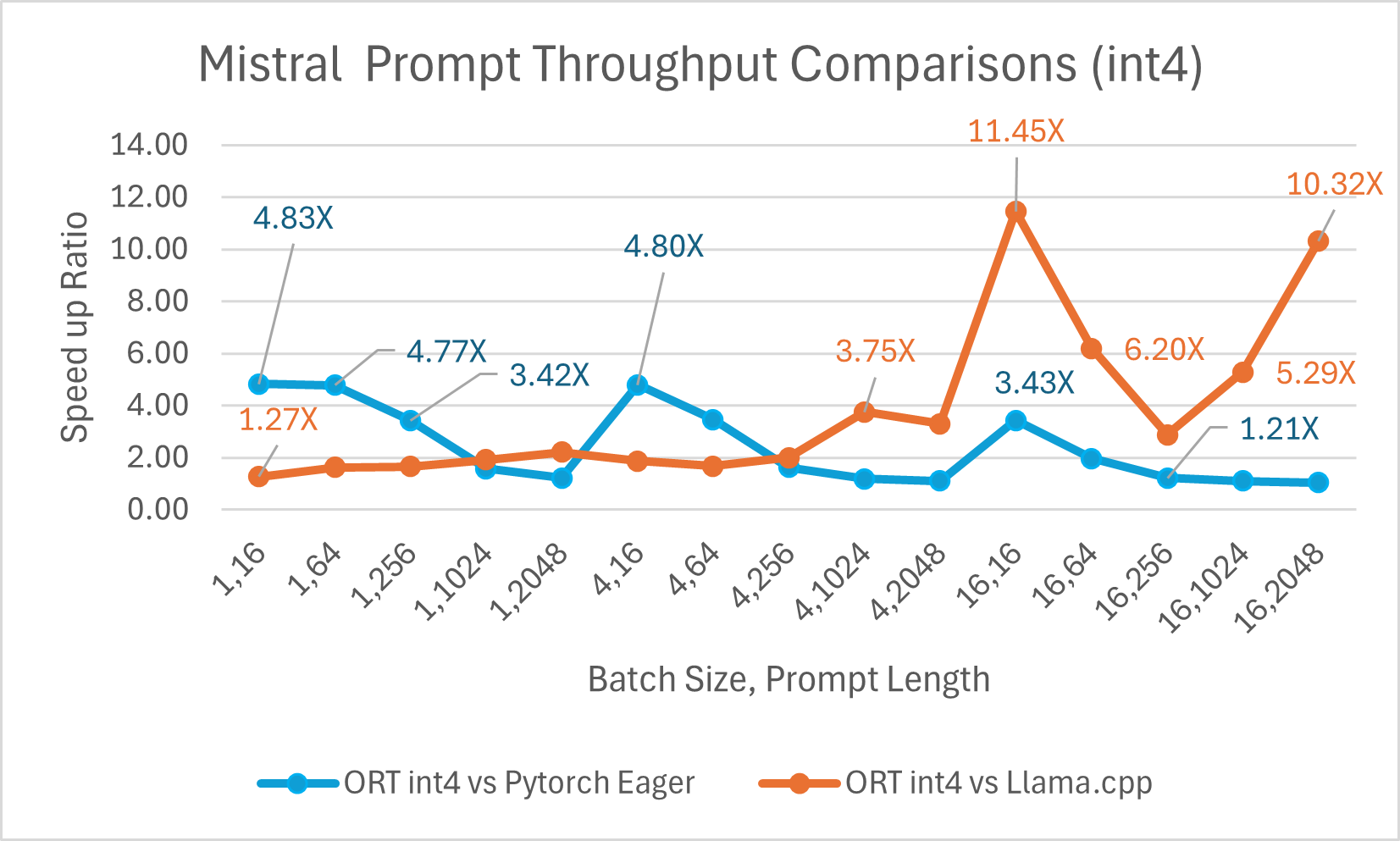
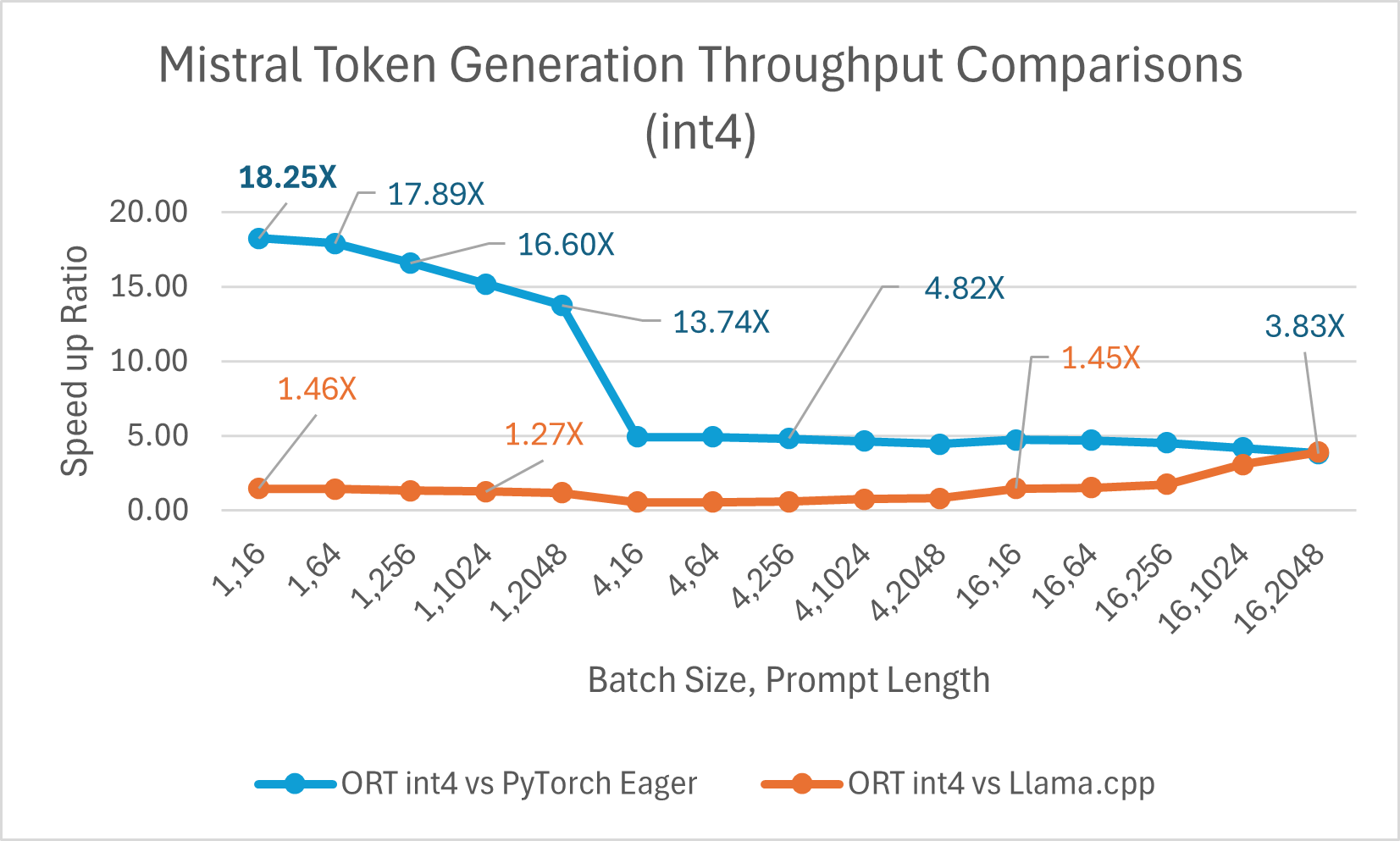
You can now access the optimized Mistral model on Huggingface here.
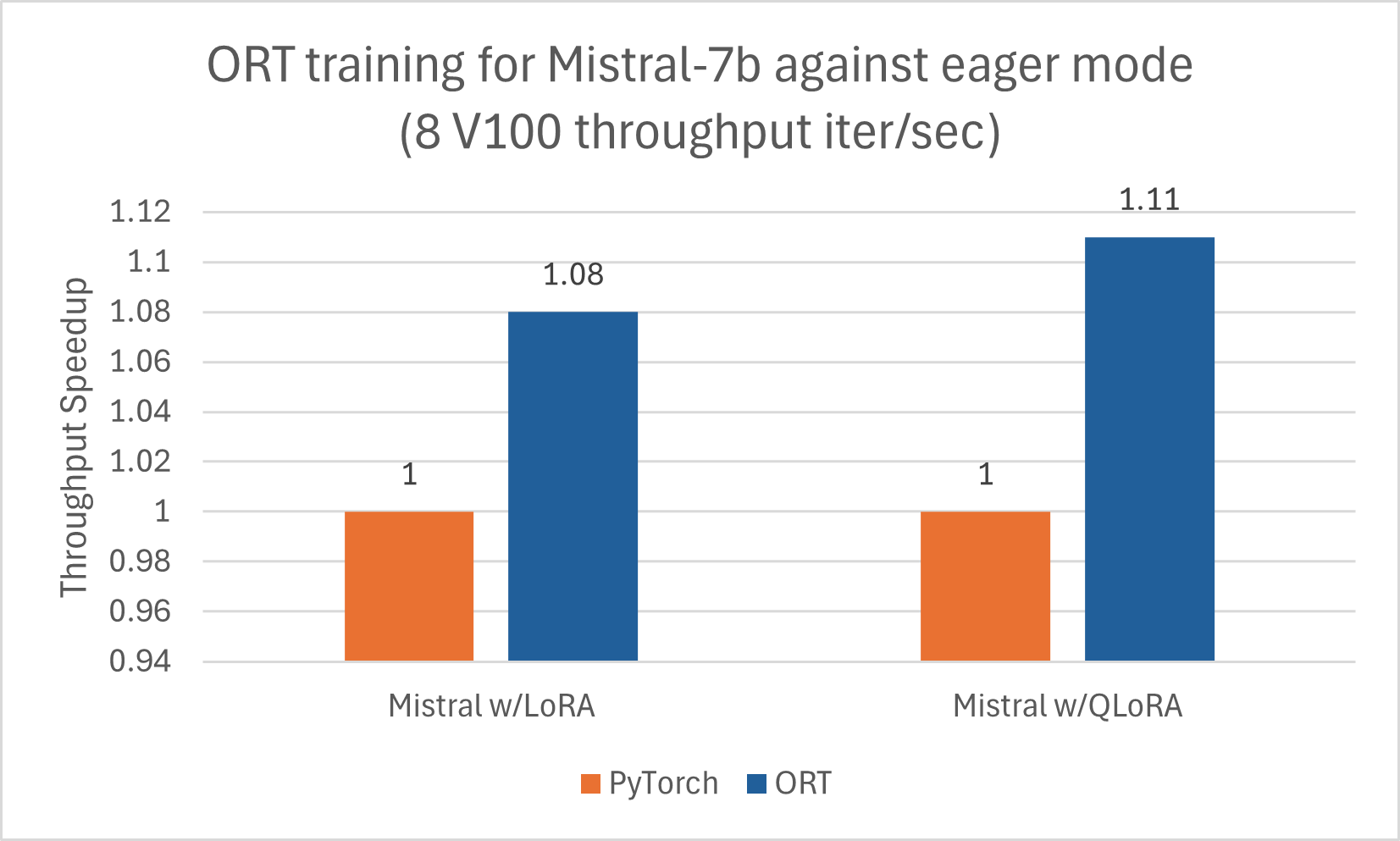
Training
Similar to Phi-2, Mistral also benefits from training acceleration using ORT. We trained Mistral-7B using the following configuration to see gains with ORT, including when composed with LoRA and QLoRA. The model was trained using DeepSpeed Stage-2 for 5 epochs, with batch size 1 on the wikitext dataset.
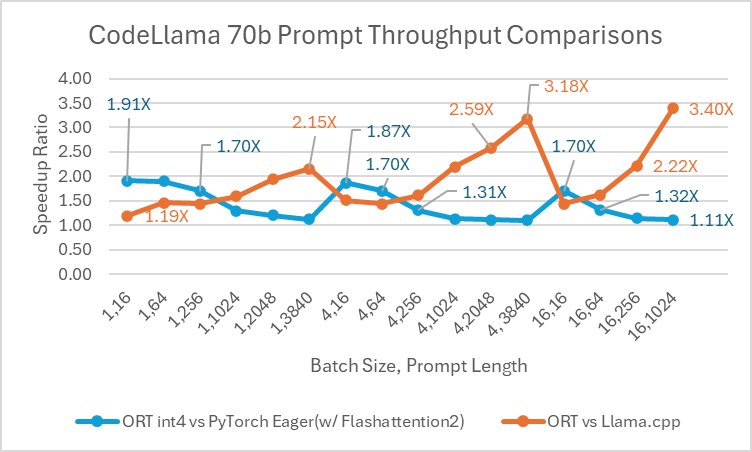
CodeLlama
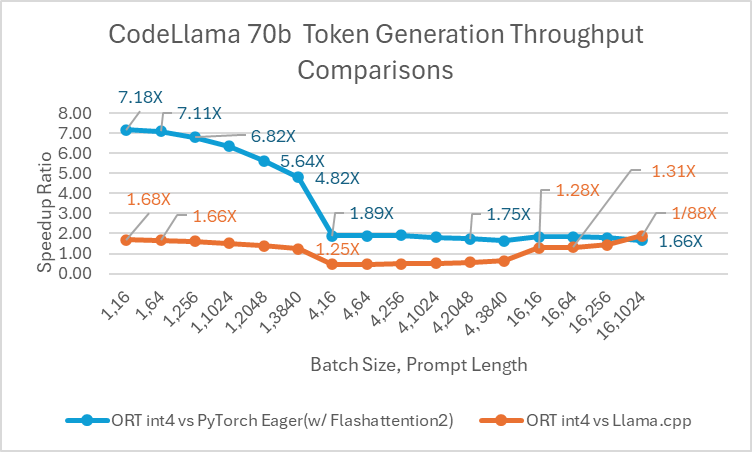
Codellama-70B is a programming-focused model developed on the Llama-2 platform. This model can produce code and generate discussions around code in natural language. Since CodeLlama-70B is a finetuned Llama model, existing optimizations can be applied directly. We compared a 4bit quantized ONNX model with PyTorch Eager and Llama.cpp. For prompt throughput, ONNX Runtime is at least 1.4x faster than PyTorch Eager for all batch sizes. ONNX Runtime produces tokens at an average speed that is 3.4x higher than PyTorch Eager for any batch size and 1.5x higher than Llama.cpp for batch size 1.
SD-Turbo and SDXL-Turbo
ONNX Runtime provides inference performance benefits when used with SD Turbo and SDXL Turbo, and it also makes the models accessible in languages other than Python, like C# and Java. ONNX Runtime achieved a higher throughput than PyTorch for all (batch size, number of steps) combinations evaluated, with throughput improvements up to 229% for the SDXL Turbo model and 120% for the SD Turbo model. ONNX Runtime CUDA is especially good at handling dynamic shape, but it also shows a significant advantage over PyTorch for static shape.
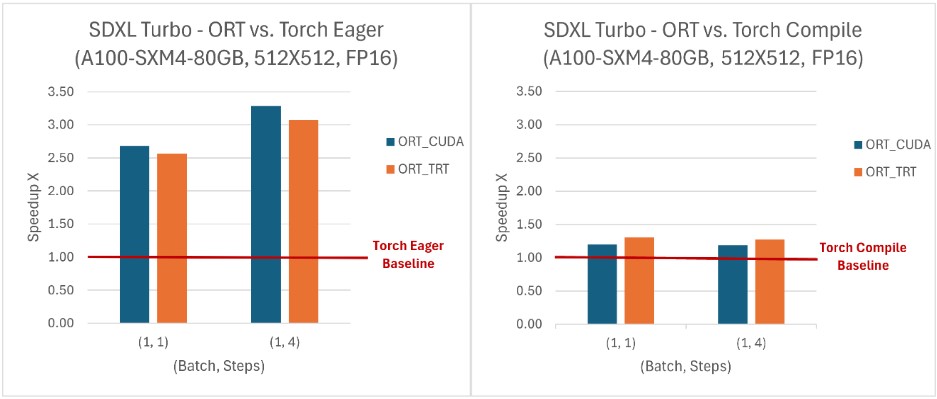
To read more about accelerating SD-Turbo and SDXL-Turbo inference with ONNX Runtime, check out our recent blog with Hugging Face.
Llama-2
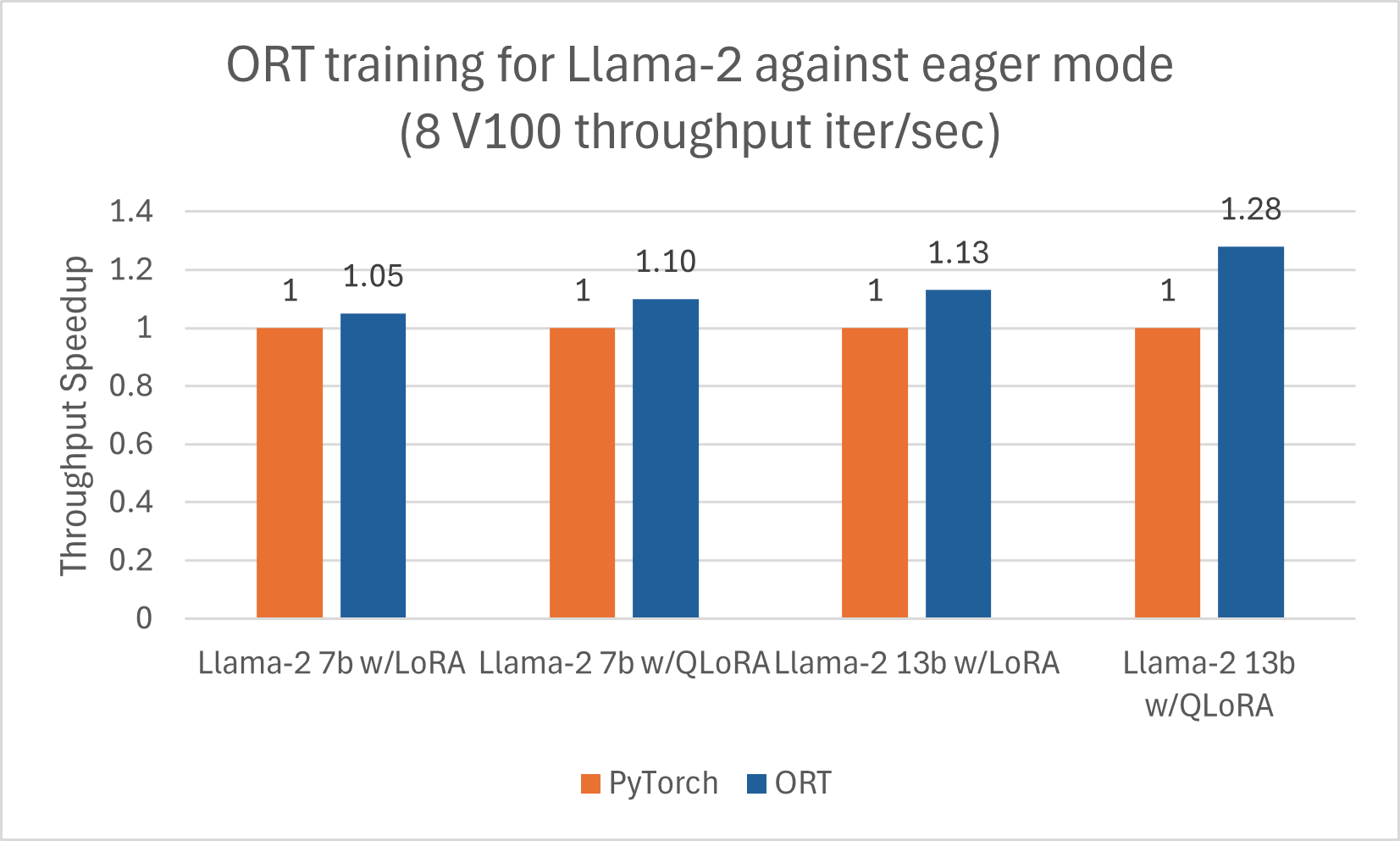
We published a separate blog for Llama-2 improvements with ORT for Inference here. Additionally, Llama-2-7B and Llama-2-13B show good gains with ORT for training, especially when combined with LoRA and QLoRA. These scripts can be used as an example to finetune Llama-2 with ORT using Optimum. The numbers below are for Llama-2 models training with ORT using DeepSpeed Stage-2 for 5 epochs, with batch size 1 on the wikitext dataset.
Orca-2
Inference
Orca-2 is a research-only system that gives a one-time answer in tasks such as reasoning with user-provided data, understanding texts, solving math problems, and summarizing texts. Orca-2 has two versions (7 billion and 13 billion parameters); they are both made by fine-tuning the respective Llama-2 base models on customized, high-quality artificial data. ONNX Runtime helps optimize Orca-2 inferencing for using graph fusions and kernel optimizations like those for Llama-2.
ORT gains with int4
Orca-2-7B int4 quantization performance comparison indicated up to 26X increase in performance in prompt throughput, and up to 16.5X improvement in token generation throughput over PyTorch. It also shows over 4.75X improvement in prompt throughput, and 3.64X improvement in token generation throughput compared to Llama.cpp.
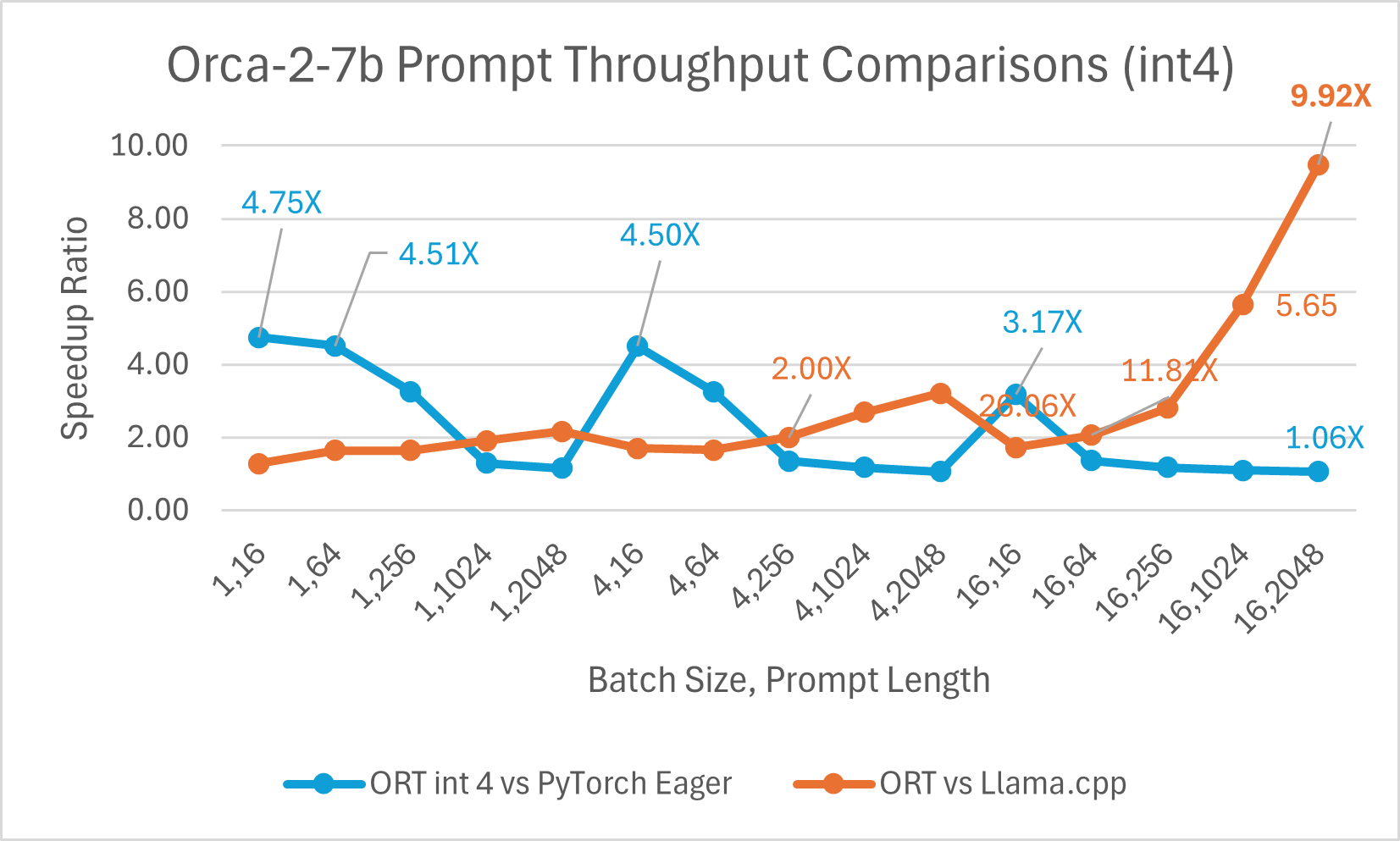
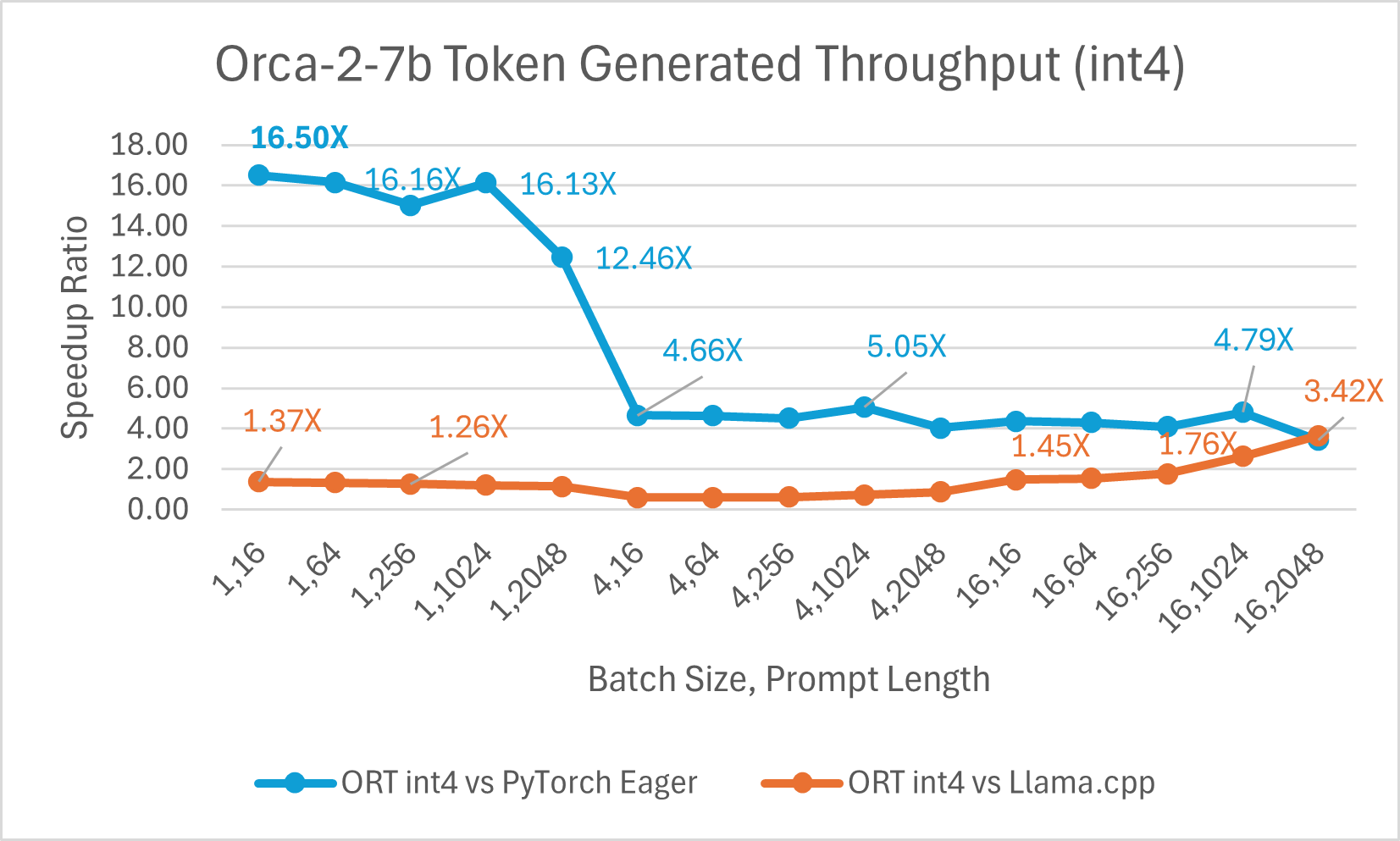
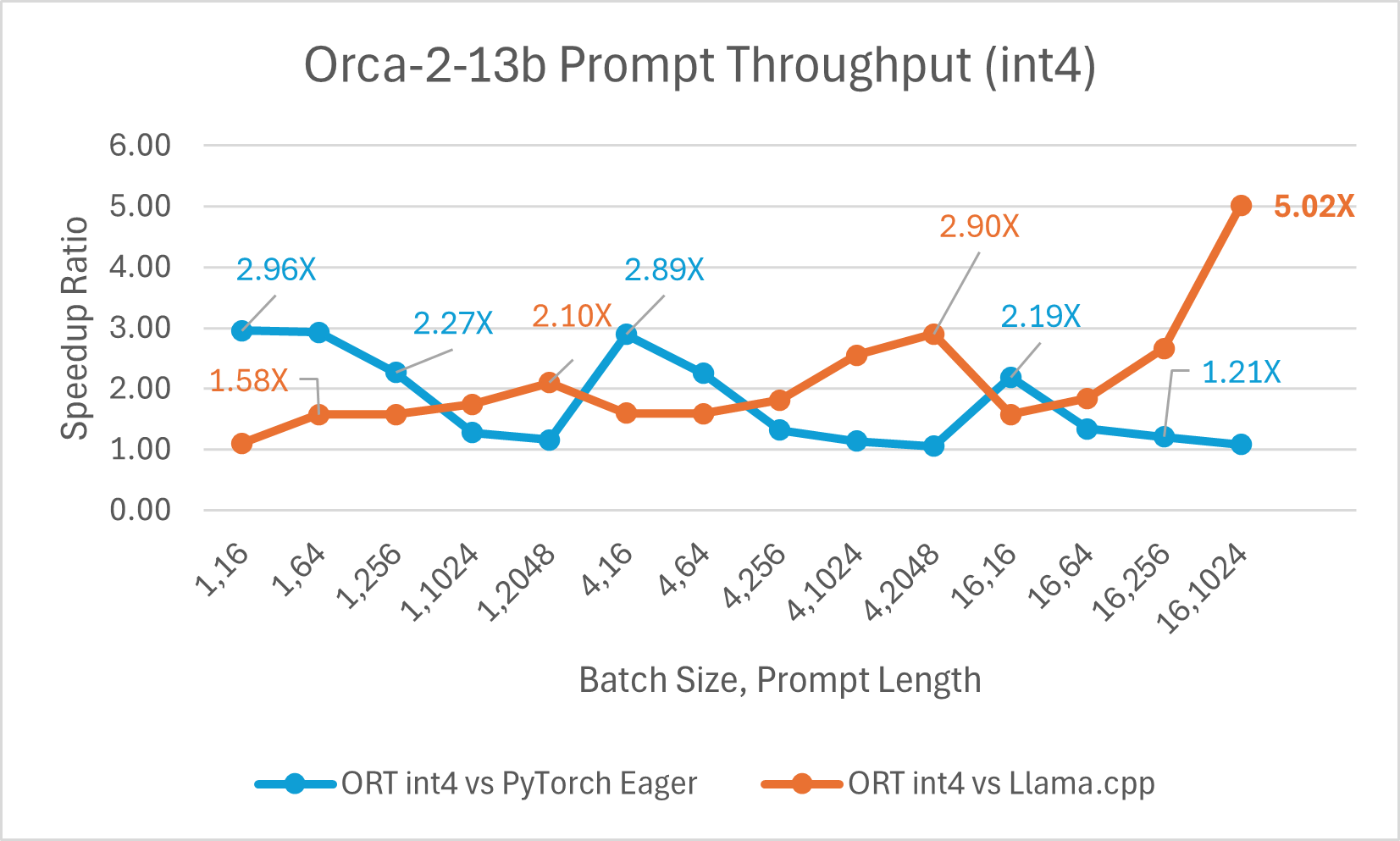
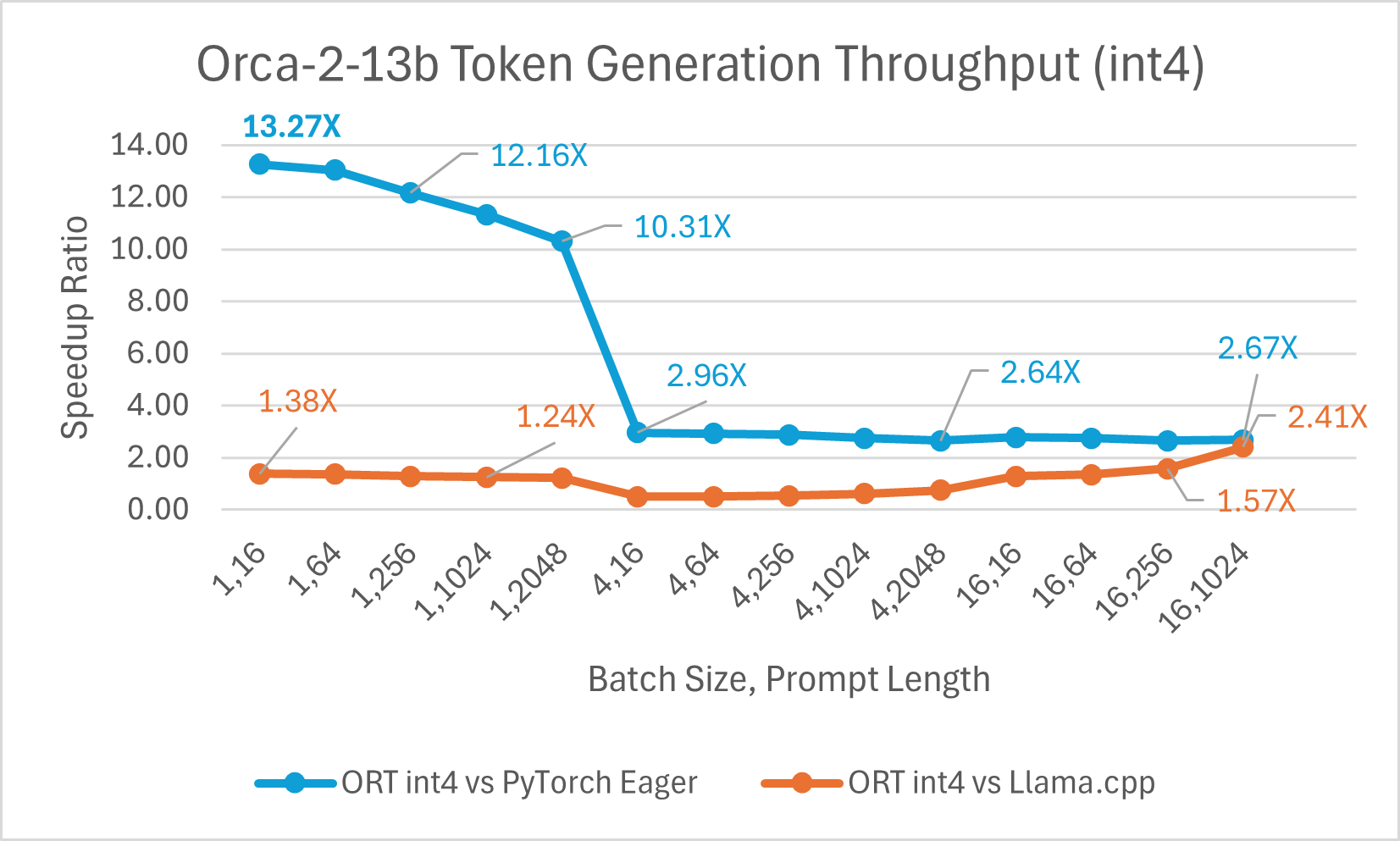
Orca-2 7b with ONNX runtime float16 performance comparison also shows significant gains in prompt and token generation throughput.
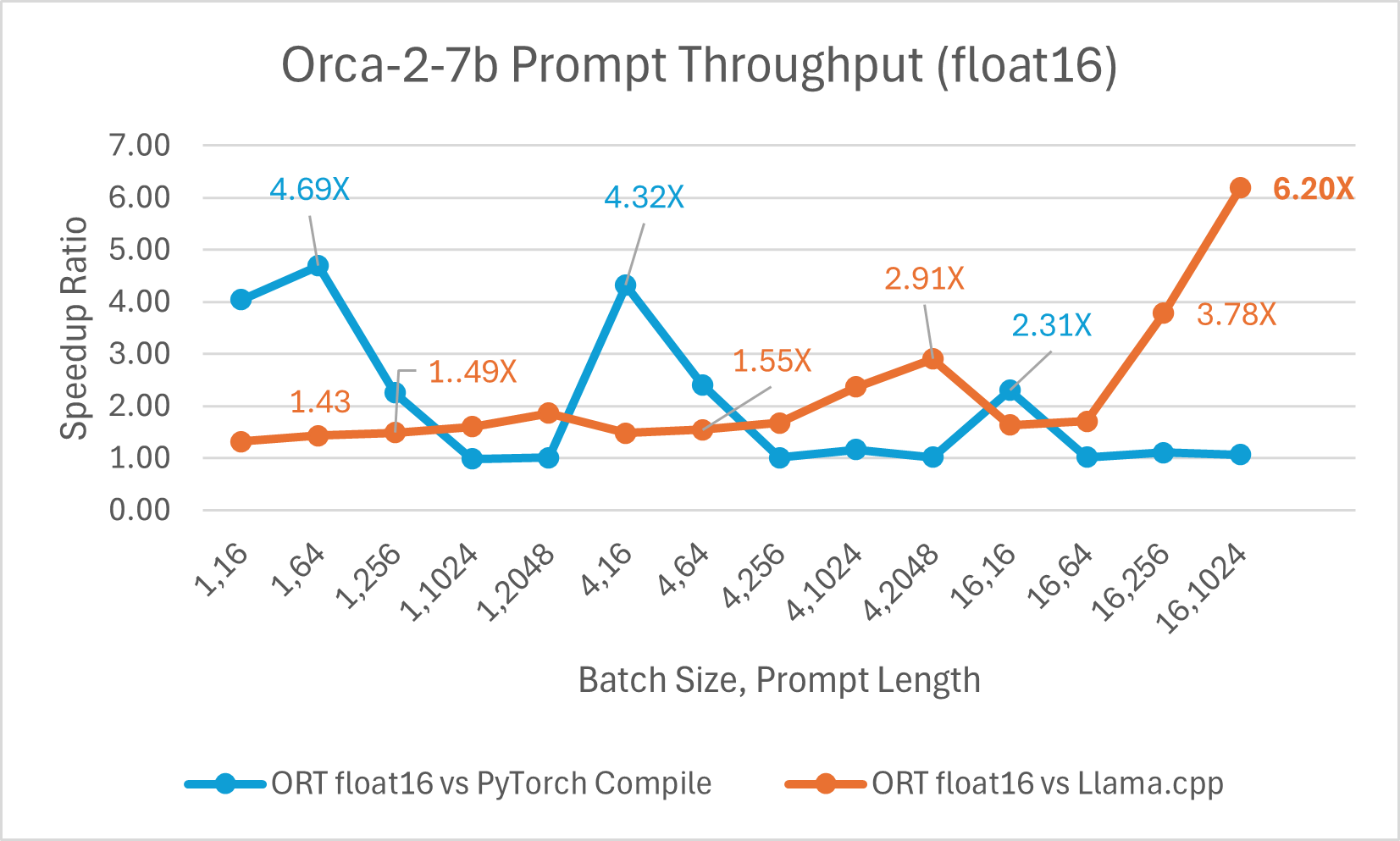
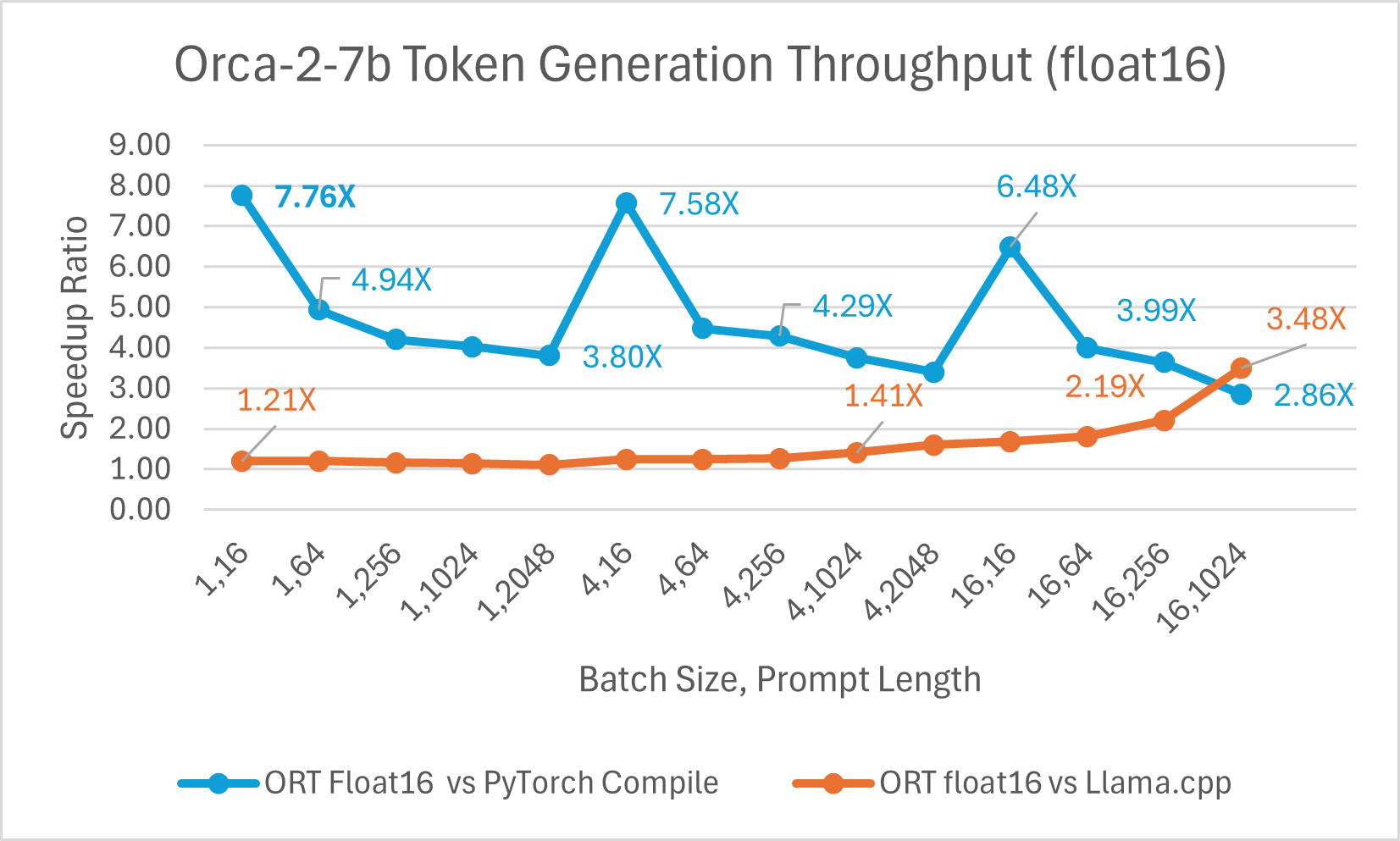
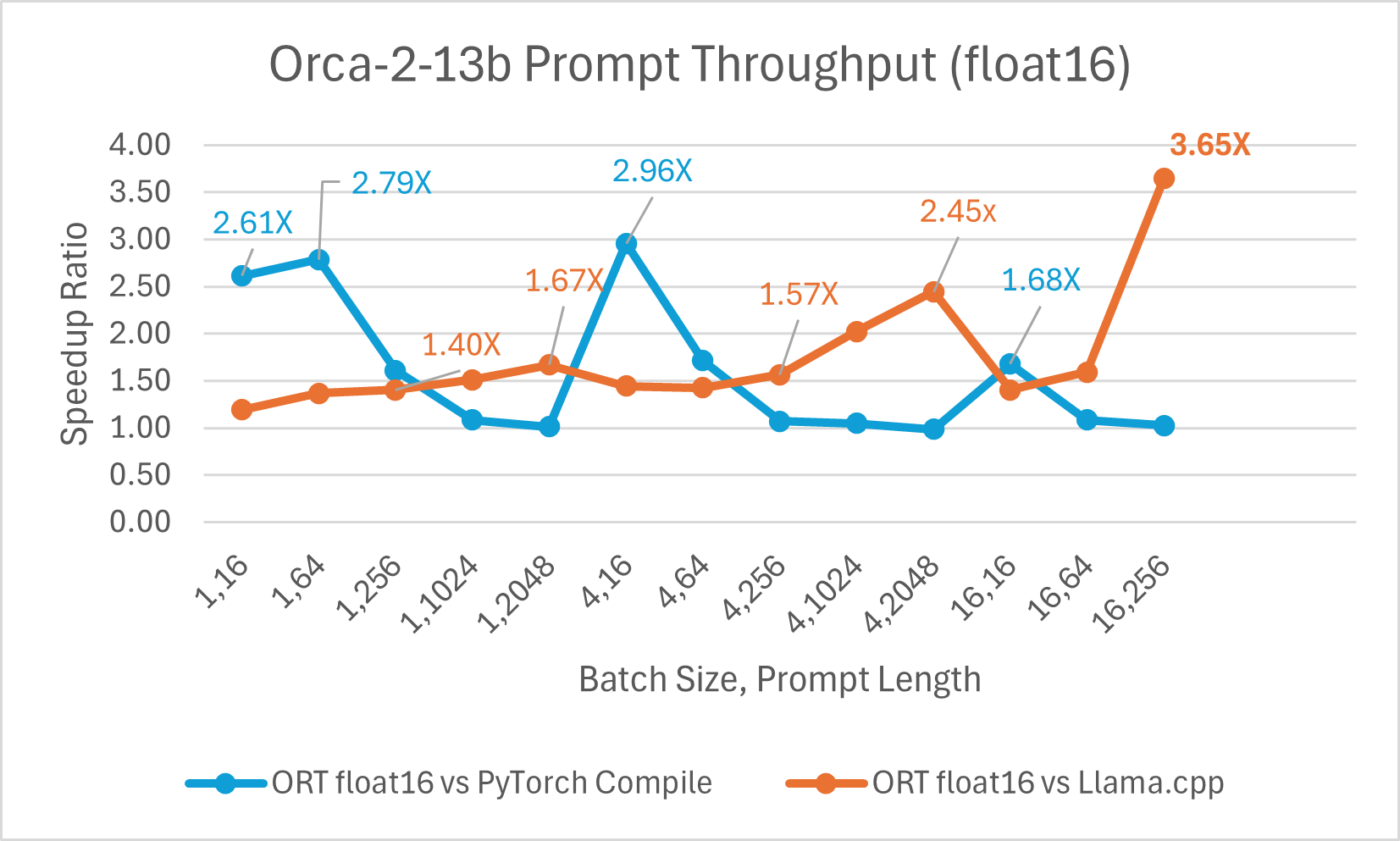
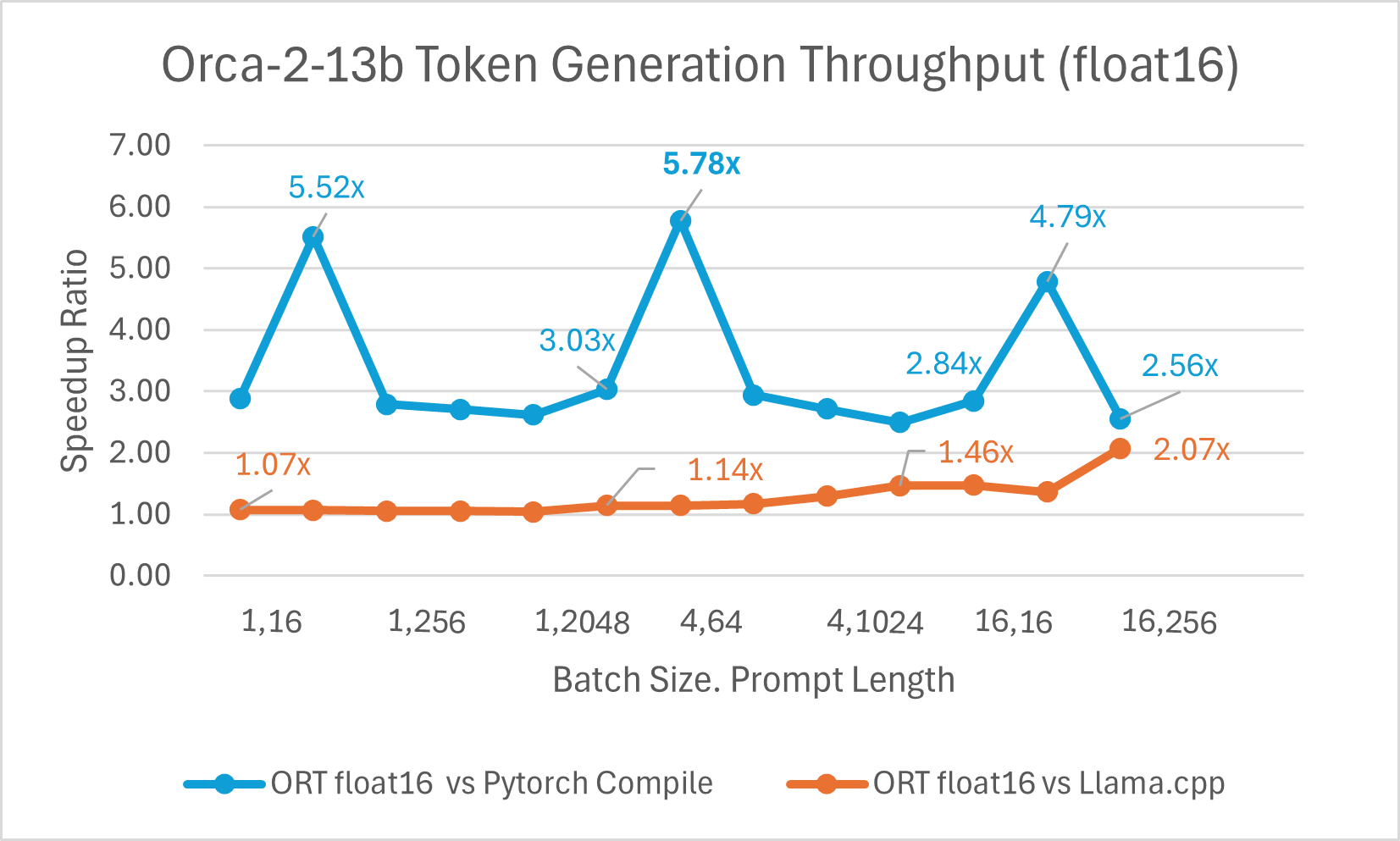
Orca-2 benchmarking done on1 A100 GPU, SKU: Standard_ND96amsr_A100_v4 , Packages torch 2.2.0, triton 2.2.0, onnxruntime-gpu 1.17.0, deepspeed 0.13.2, llama.cpp - commit 594fca3fefe27b8e95cfb1656eb0e160ad15a793, transformers 4.37.2
Training
Orca-2-7B also benefits from training acceleration using ORT. We trained the Orca-2-7B model for a sequence length of 512 with LoRA and with the sparsity optimization enabled and saw good gains in performance. The numbers below are for Orca-2-7B models trained with ORT using DeepSpeed Stage-2 for 5 epochs, with batch size 1 on the wikitext dataset.
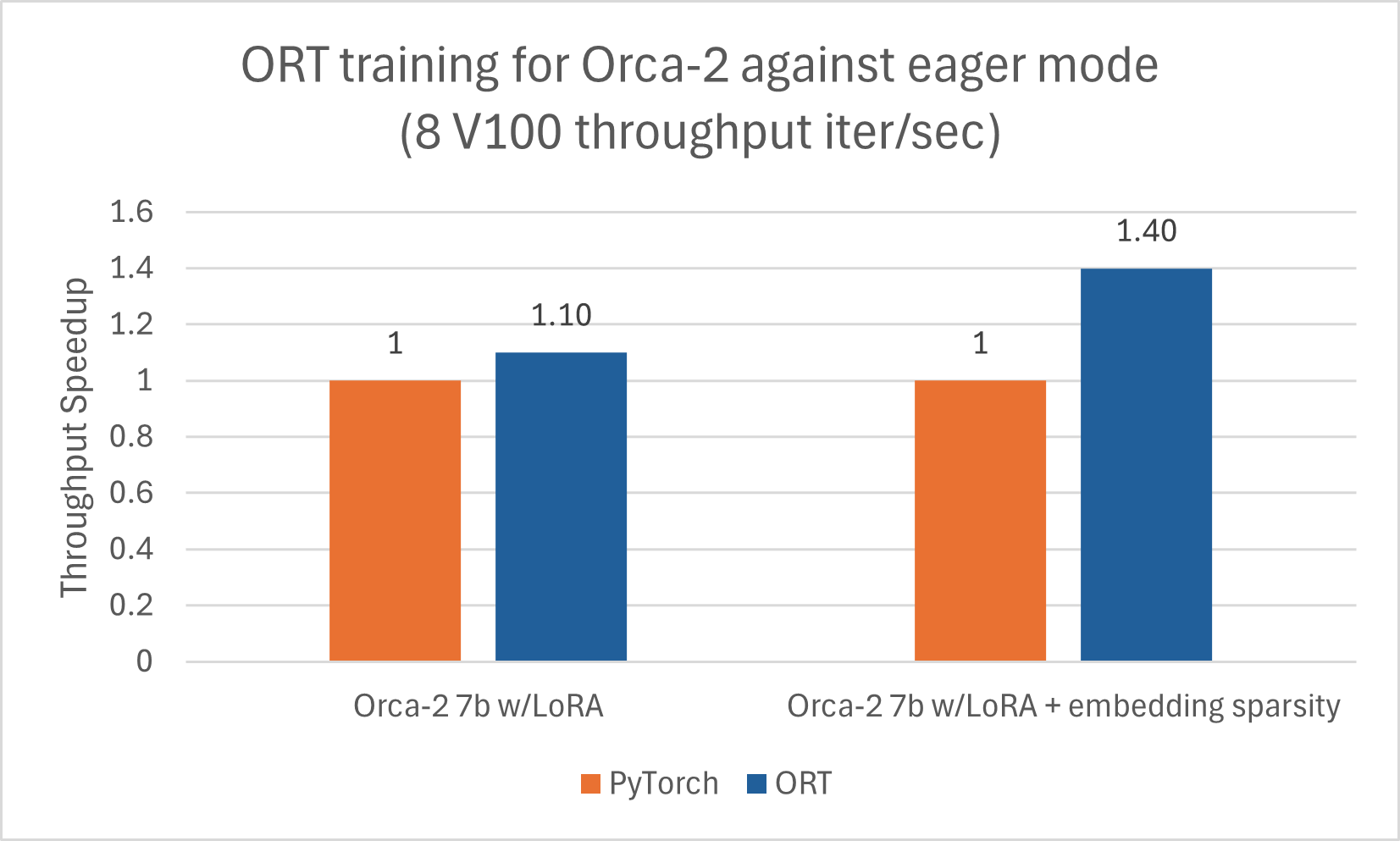 Uses ACPT image: nightly-ubuntu2004-cu118-py38-torch230dev:20240131
Uses ACPT image: nightly-ubuntu2004-cu118-py38-torch230dev:20240131 Gemma
Gemma is a family of lightweight, open models built from the research and technology that Google used to create Gemini models. It is available in two sizes: 2B and 7B. Each size is released with pre-trained and instruction-tuned variants. ONNX Runtime can be used to optimize and efficiently run any open-source model. We benchmarked against the Gemma-2B model, and ONNX Runtime with float16 is up to 7.47x faster than PyTorch Compile and up to 3.47x faster than Llama.cpp. ORT with int4 quantization is up to 19.81x faster than PyTorch Eager and 2.62x faster than Llama.cpp.
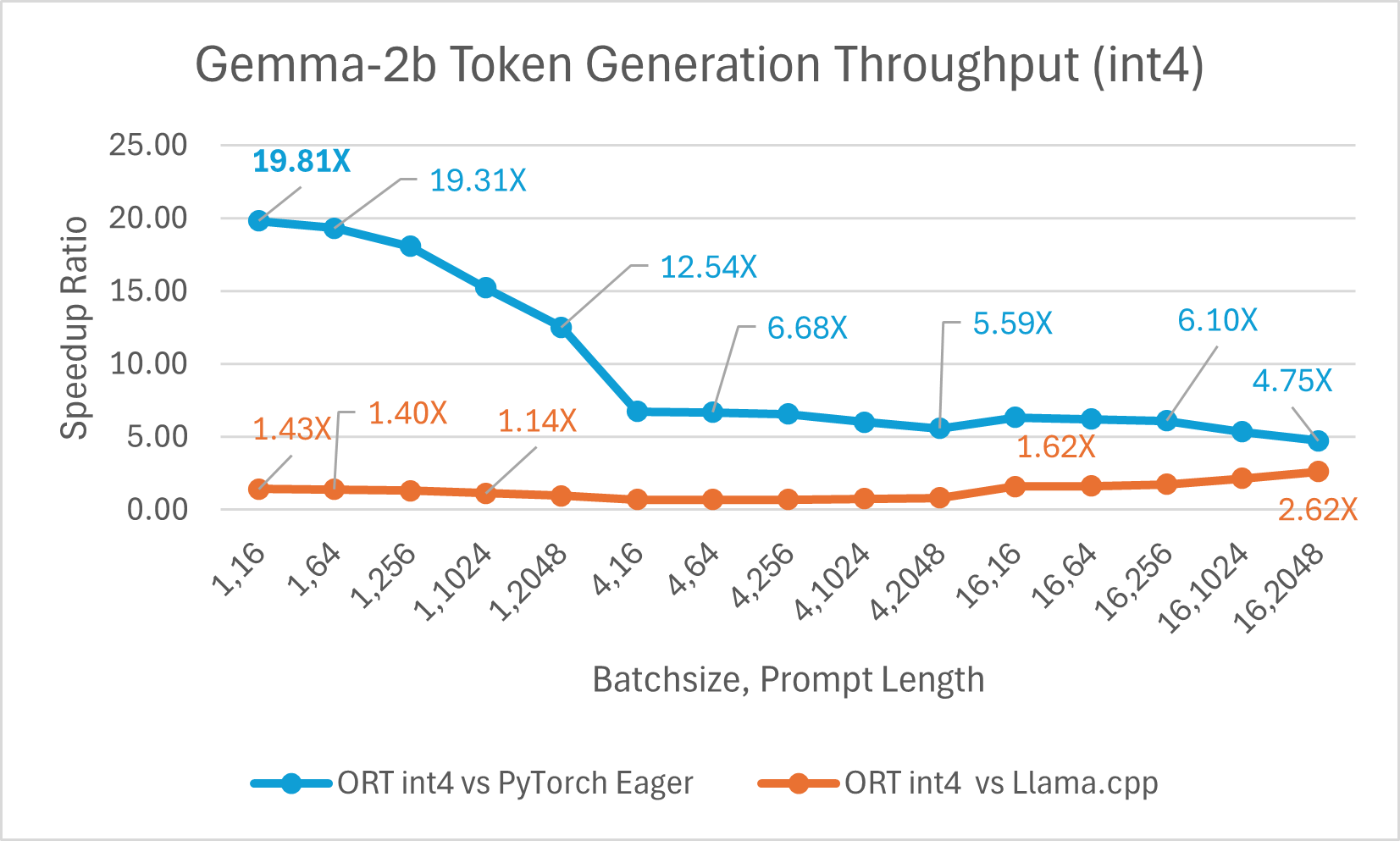
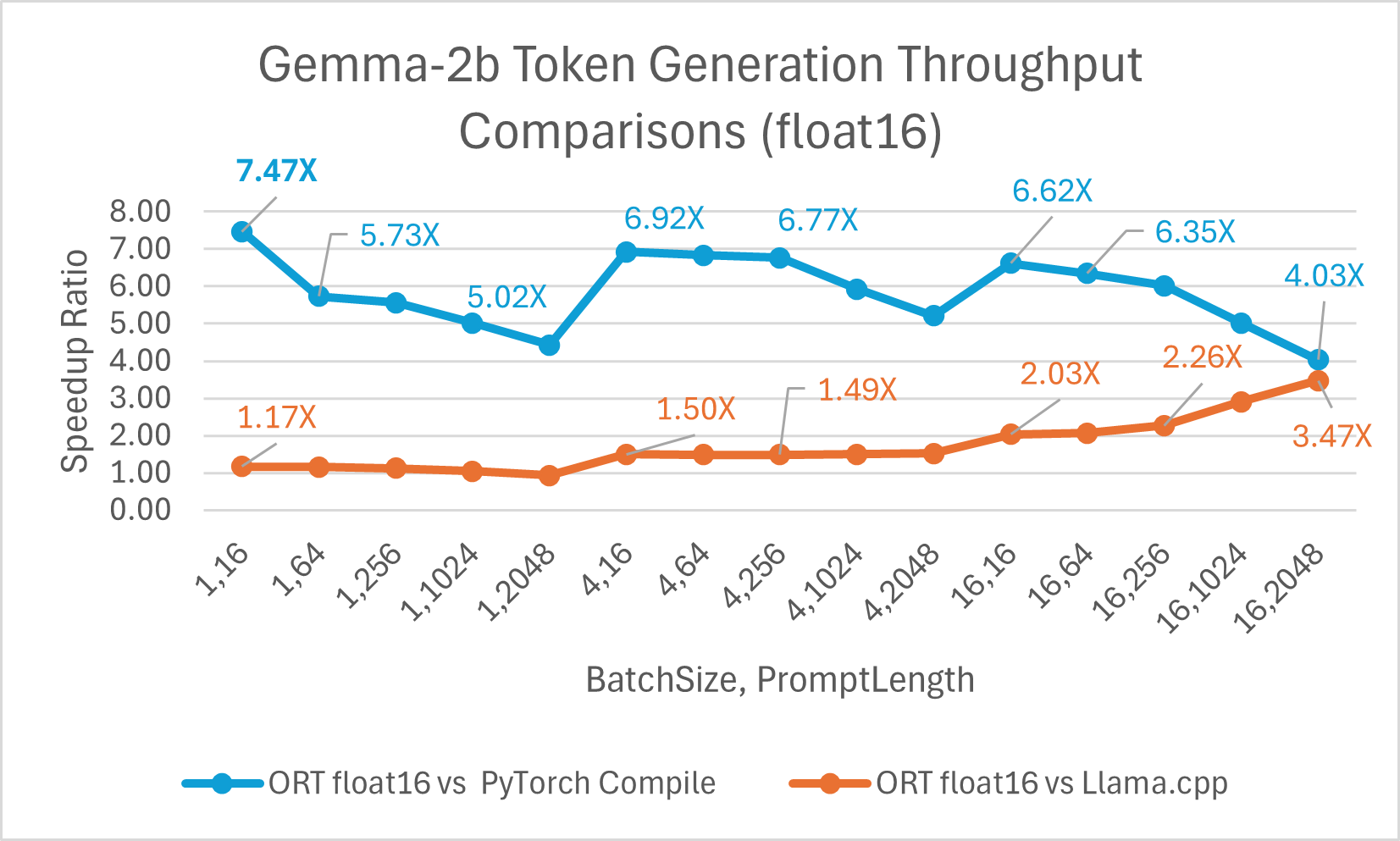
Conclusion
In conclusion, ONNX Runtime (ORT) provides significant performance improvements for several models, including Phi-2, Mistral, CodeLlama, SDXL-Turbo, Llama-2, Orca-2, and Gemma. ORT offers state-of-the-art fusion and kernel optimizations, including support for float16 and int4 quantization, resulting in faster inferencing speeds and lower costs. ORT outperforms other frameworks like PyTorch and Llama.cpp in terms of prompt and token generation throughput. ORT also shows significant benefits for training LLMs, with increasing gains for larger batch sizes, and composes well with state-of-the-art techniques to enable efficient large model training.