Is it better to quantize before or after finetuning?
By:
Jambay Kinley, Sam Kemp19TH NOVEMBER, 2024
👋 Introduction
Quantization in machine learning is a technique used to reduce the precision of the numbers used in computations, which helps in making models more efficient. Instead of using high-precision floating point numbers (like 32-bit or 16-bit), quantization converts these numbers to lower-precision formats, such as 8-bit integers. The primary benefits of quantization are a smaller model size and faster computations, which are particularly useful for deploying models on devices with limited resources, like mobile phones or embedded systems. However, this reduction in precision can sometimes lead to a slight decrease in the model’s accuracy.
Fine-tuning an AI model using the LoRA (Low-Rank Adaptation) method is an efficient way to adapt large language models to specific tasks or domains. Instead of retraining all the model parameters, LoRA modifies the fine-tuning process by freezing the original model weights and applying changes to a separate set of weights, which are then added to the original parameters. This approach transforms the model parameters into a lower-rank dimension, reducing the number of parameters that need training, thus speeding up the process and lowering costs.
When fine-tuning and quantizing a model, it is important to establish the correct sequence:
- Is it better to quantize before fine-tuning or after?
In theory, quantizing before fine-tuning should produce a better model as LoRA weights are trained with the same quantized base model weights they will be deployed with. This avoids the accuracy loss that occurs when training on float base weights and then deploying with a quantized base model. In this blog post we demonstrate how Olive - a state-of-the-art model optimization toolkit for the ONNX runtime - can help you answer when to quantize and which quantization algorithm to use for a given model architecture and scenario.
Also, as part of answering the question of when to quantize we’ll show how the following different quantization algorithms impact accuracy:
- Activation-Aware Weight Quantization (AWQ) is a technique designed to optimise large language models (LLMs) for efficient execution. AWQ quantizes the weights of a model by considering the activations produced during inference. This means that the quantization process takes into account the actual data distribution in the activations, leading to better preservation of model accuracy compared to traditional weight quantization methods
- Generalized Post-Training Quantization (GPTQ) is a post-training quantization technique designed for Generative Pre-trained Transformer (GPT) models. It quantizes the weights of the model to lower bitwidths, such as 4-bit integers, to reduce memory usage and computational requirements without significantly impacting the model’s accuracy. This technique quantizes each row of the weight matrix independently to find a version of the weights that minimizes error
⚗️ Running the experiment with Olive
To answer our question on the right sequencing of quantization and fine-tuning we leveraged Olive (ONNX Live) - an advanced model optimization toolkit designed to streamline the process of optimizing AI models for deployment with the ONNX runtime.
Note: Both quantization and fine-tuning need to run on an Nvidia A10 or A100 GPU machine.
1. 💾 Install Olive
We installed the Olive CLI using pip:
pip install olive-ai[finetune]
pip install autoawq
pip install auto-gptq
2. 🗜️ Quantize
We quantize Phi-3.5-mini-instruct using both the AWQ and GPTQ algorithms with the following Olive commands:
# AWQ Quantization
olive quantize \
--algorithm awq \
--model_name_or_path microsoft/Phi-3.5-mini-instruct \
--output_path models/phi-awq
# GPTQ Quantization
olive quantize \
--algorithm gptq \
--model_name_or_path microsoft/Phi-3.5-mini-instruct \
--data_name wikitext \
--subset wikitext-2-raw-v1 \
--split train \
--max_samples 128 \
--output_path models/phi-gptq
3. 🎚️ Fine-tune
We fine-tune the quantized models using the tiny codes dataset from Hugging Face. This is a gated dataset and you’ll need to request for access. Once access has been granted you should login into Hugging Face with your access token:
huggingface-clu login --token TOKEN
Olive can finetune using the following commands:
# Finetune AWQ model
olive finetune \
--model_name_or_path models/phi-awq \
--data_name nampdn-ai/tiny-codes \
--train_split "train[:4096]" \
--eval_split "train[4096:4224]" \
--text_template "### Language: {programming_language} \n### Question: {prompt} \n### Answer: {response}" \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--max_steps 100 \
--logging_steps 25 \
--output_path models/phi-awq-ft
# Finetune GPTQ model
olive finetune \
--model_name_or_path models/phi-gptq \
--data_name nampdn-ai/tiny-codes \
--train_split "train[:4096]" \
--eval_split "train[4096:4224]" \
--text_template "### Language: {programming_language} \n### Question: {prompt} \n### Answer: {response}" \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--max_steps 100 \
--logging_steps 25 \
--output_path models/phi-gptq-ft
Note: We also did the reverse sequence where we Fine-tuned first and then ran quantization. They are the same commands but in a different order.
4. 🎯 Run perplexity
We ran a perplexity metrics on the models using Olive. First, we defined the following Olive configuration in a file called perplexity-config.yaml, which uses Olive’s evaluation feature:
input_model:
type: HfModel
model_path: models/phi-awq-ft/model
adapter_path: models/phi-awq-ft/adapter
systems:
local_system:
type: LocalSystem
accelerators:
- device: gpu
execution_providers:
- CUDAExecutionProvider
data_configs:
- name: tinycodes_ppl
type: HuggingfaceContainer
load_dataset_config:
data_name: nampdn-ai/tiny-codes
split: 'train[5000:6000]'
pre_process_data_config:
text_template: |-
### Language: {programming_language}
### Question: {prompt}
### Answer: {response}
strategy: line-by-line
max_seq_len: 1024
dataloader_config:
batch_size: 8
evaluators:
common_evaluator:
metrics:
- name: tinycodes_ppl
type: accuracy
sub_types:
- name: perplexity
data_config: tinycodes_ppl
passes: {}
auto_optimizer_config:
disable_auto_optimizer: true
evaluator: common_evaluator
host: local_system
target: local_system
output_dir: models/eval
Note: We define the same configurations for the other models but updated the
input_model.
We then executed the Olive configuration using:
olive run --config perplexity-config.yaml📊 Results
Phi-3.5-Mini-Instruct
The chart below shows the perplexity metrics for the:
- Different Quantization and Fine-tuning sequences (magenta)
- Phi-3.5-Mini-Instruct base model (dashed green line), which is not quantized
- Phi-3.5-Mini-Instruct Fine-tuned model (solid green line), which is not quantized
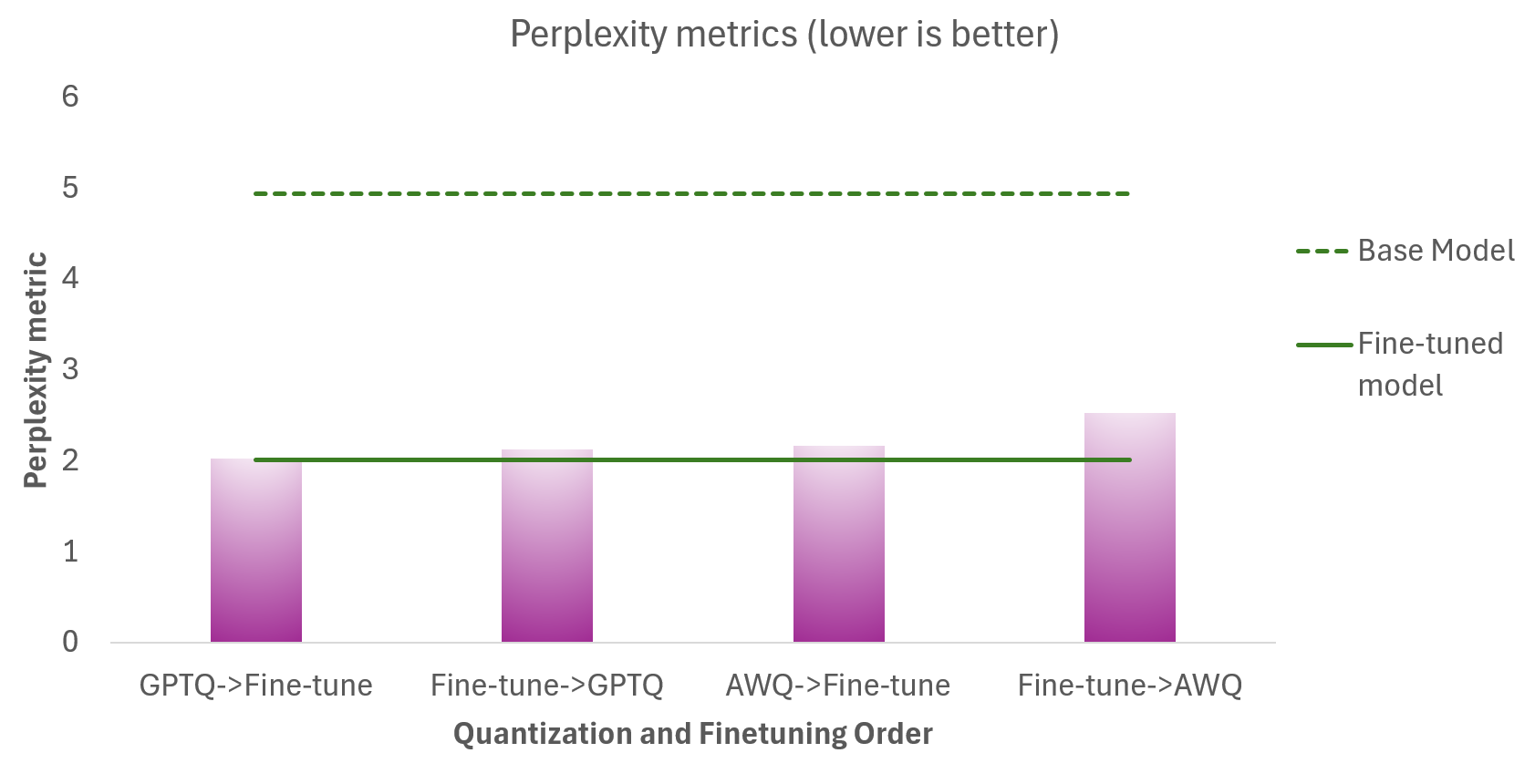
The goal is for the quantized models to be as close to the fine-tuned model (solid green line) as possible. There are several takeaways:
- Quantization does not have a significant impact on the model quality - as seen by the closeness of the perplexity scores for quantized models to the fine-tuned base model.
- Quantizing before fine-tuning does give better results than quantizing after finetuning.
- GPTQ provides better accuracy in this scenario than AWQ.
Llama-3.1-8B-Instruct
The chart below shows the perplexity metrics for the:
- Different Quantization and Fine-tuning sequences (blue)
- Llama-3.1-8B-Instruct base model (dashed green line), which is not quantized
- Llama-3.1-8B-Instruct Fine-tuned model (solid green line), which is not quantized
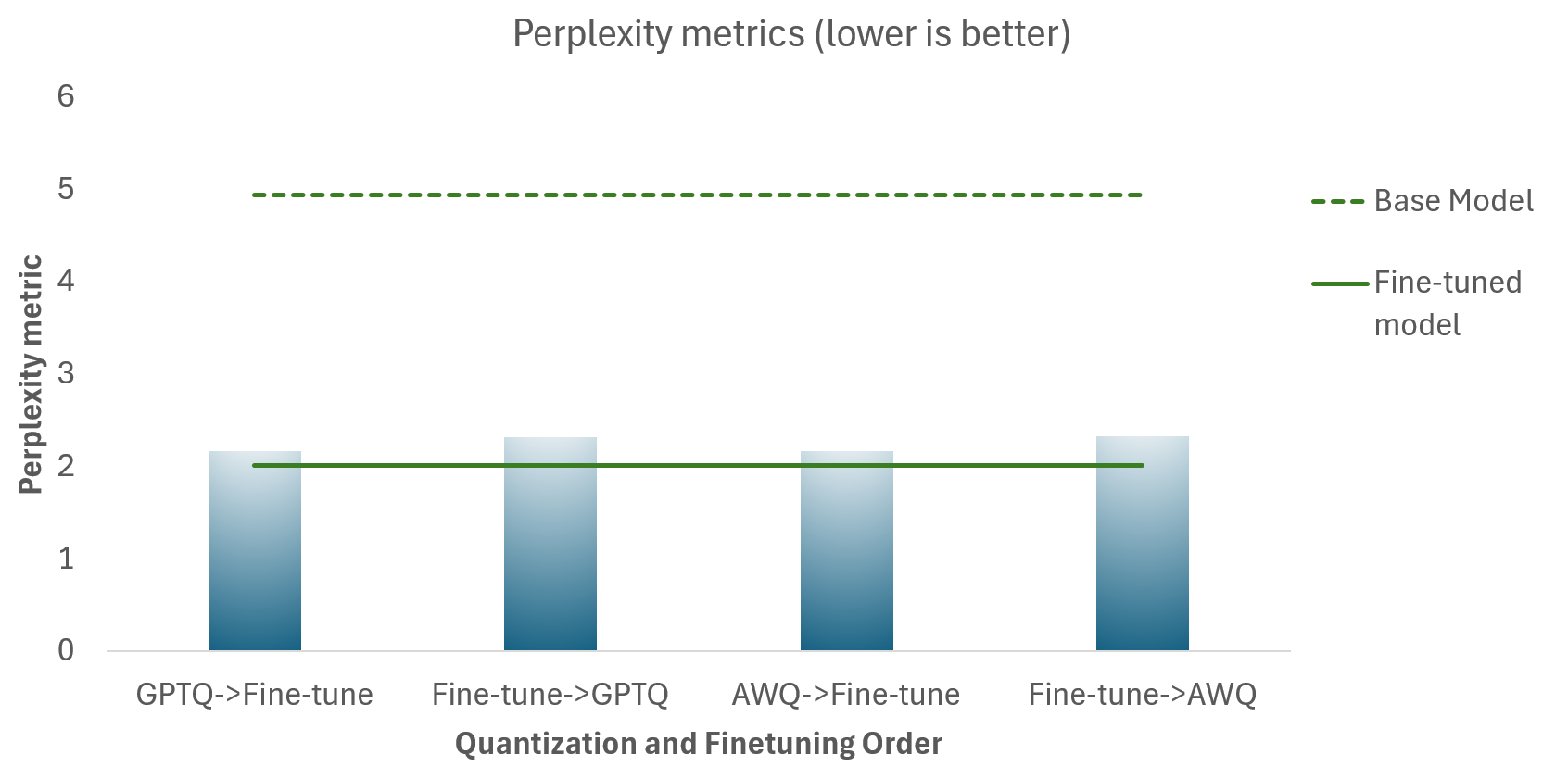
The goal is for the quantized models to be as close to the fine-tuned model (solid green line) as possible. There are several takeaways:
- Quantization does not have a significant impact on the model quality - as seen by the closeness of the perplexity scores for quantized models to the fine-tuned base model.
- Quantizing before fine-tuning does give better results than quantizing after finetuning.
- GPTQ and AWQ give similar model quality results.
Conclusion
In this blog post, we demonstrated how we utilised Olive to address common AI model optimisation queries. Our findings revealed that quantizing before fine-tuning enhances model quality for both Phi-3.5-mini-instruct and Llama-3.1-8B-Instruct. These quantied variants closely match the quality of their full precision (FP32) counterparts, while requiring less memory and storage. This underscores the potential for on-device AI to deliver high-quality performance with a reduced resource footprint.