Democratizing AI Model optimization with the new Olive CLI
By:
Jambay Kinley, Hitesh Shah, Xiaoyu Zhang, Devang Patel, Sam Kemp11TH NOVEMBER, 2024
👋 Introduction
At Build 2023 Microsoft announced Olive (ONNX Live): an advanced model optimization toolkit designed to streamline the process of optimizing AI models for deployment with the ONNX runtime. As articulated in the following diagram, Olive can take models from frameworks like PyTorch or Hugging Face and output optimized ONNX models tailored for specific deployment targets.
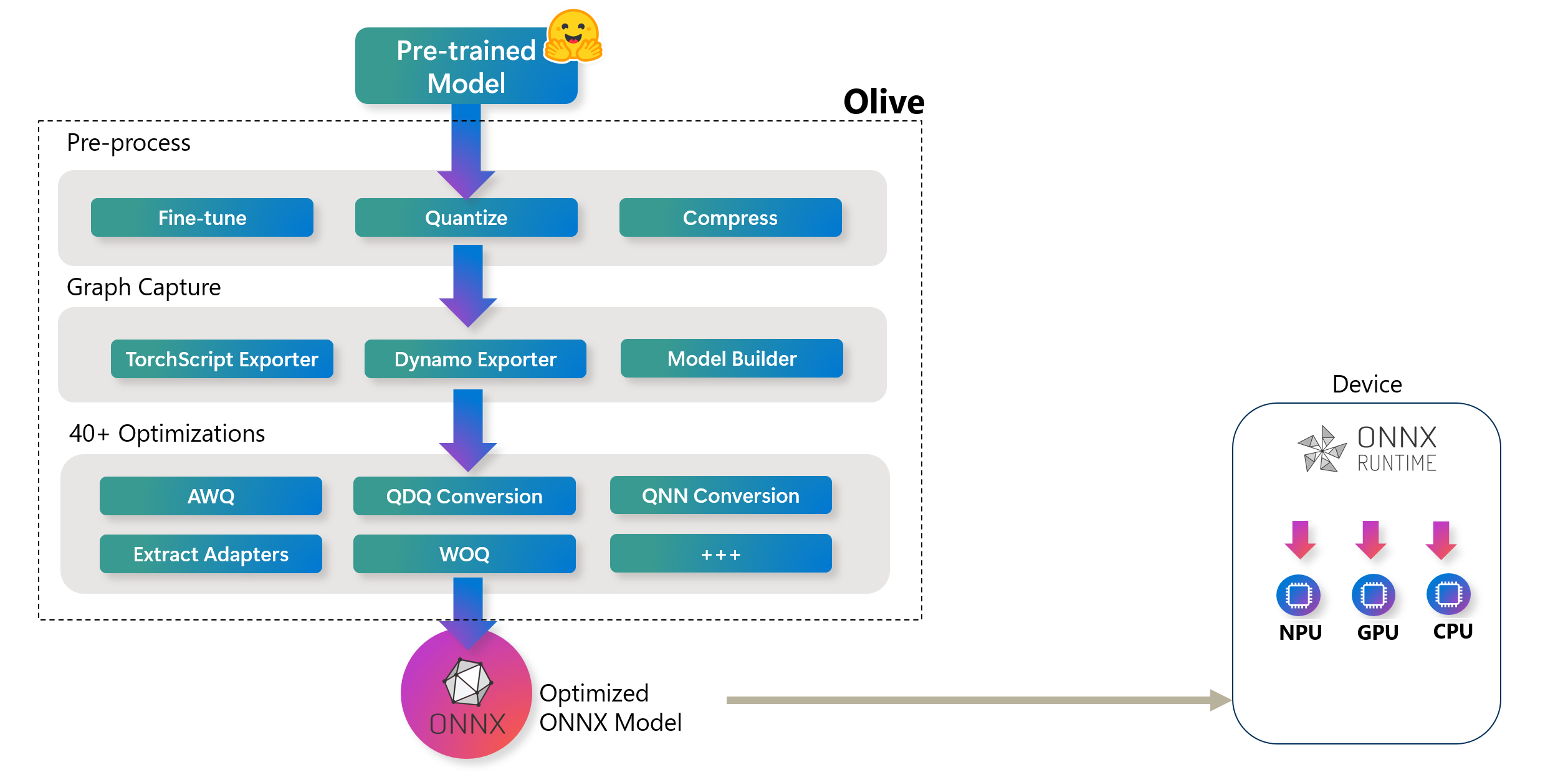 High-Level Olive Workflow. These hardware targets can include various AI accelerators (GPU, CPU) provided by major hardware vendors such as Qualcomm, AMD, Nvidia, and Intel
High-Level Olive Workflow. These hardware targets can include various AI accelerators (GPU, CPU) provided by major hardware vendors such as Qualcomm, AMD, Nvidia, and IntelOlive operates through a structured workflow consisting of a series of model optimization tasks known as passes. These passes can include model compression, graph capture, quantization, and graph optimization. Each pass has adjustable parameters that can be tuned to achieve optimal metrics like accuracy and latency, which are assessed by respective evaluators. The tool leverages a search strategy, employing algorithms to auto-tune either individual passes or sets of passes collectively, ensuring the best possible performance for the deployment targets.
Whilst the workflow paradigm used in Olive is very flexible, the learning curve can be challenging for AI Developers new to model optimization processes. To make model optimization more approachable, we have curated a set of Olive workflows for common scenarios and exposed them as a simple command in a new easy-to-use CLI for Olive:
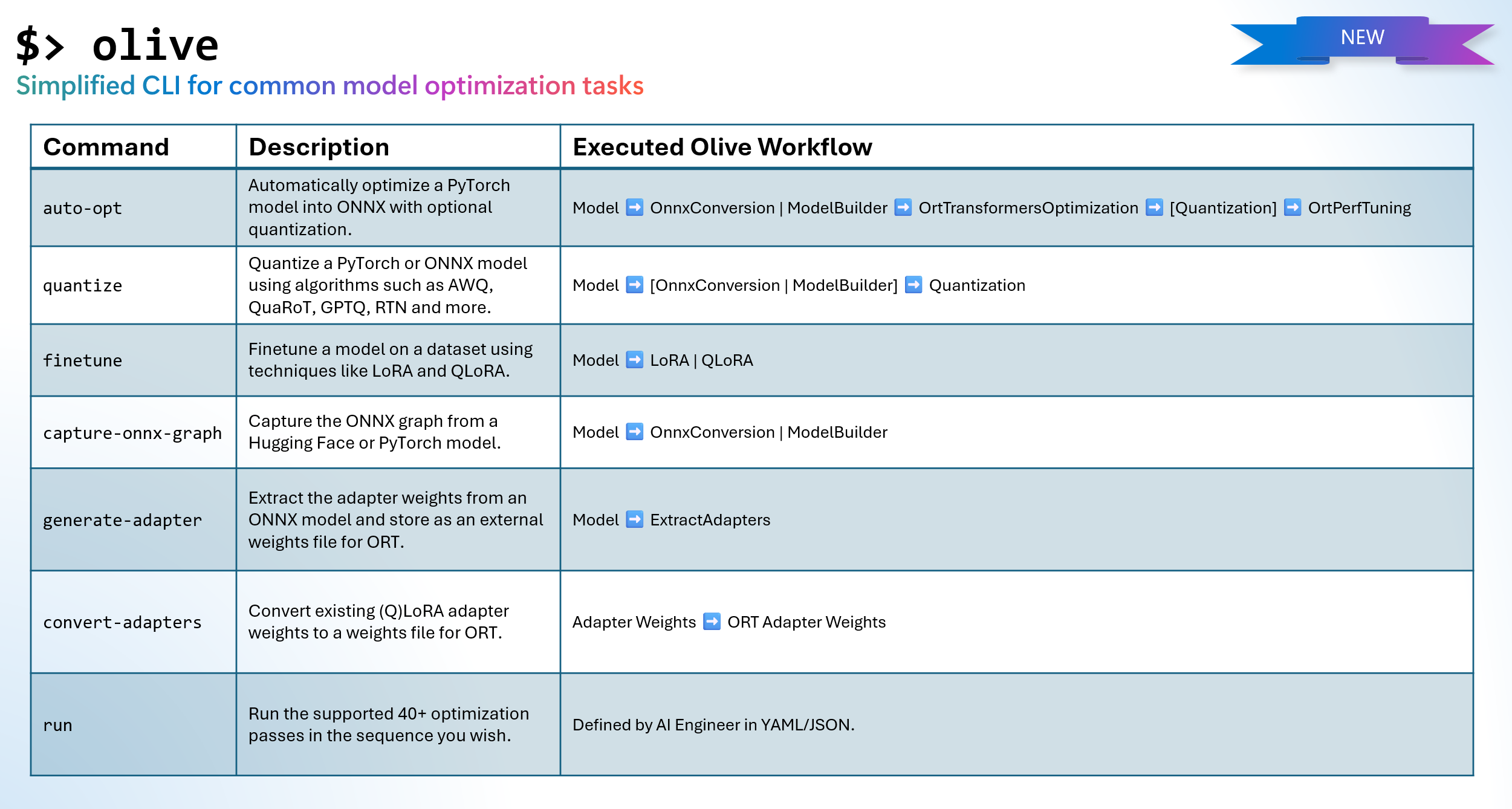 Mapping of new Olive CLI commands to the associated Olive workflow that is executed.
Mapping of new Olive CLI commands to the associated Olive workflow that is executed.In this blog, we’ll show you how to prepare models for the ONNX Runtime using the Olive CLI.
🚀 Getting started with the Olive CLI
First, install Olive using pip:
pip install olive-ai[cpu,finetune]🪄 Automatic optimizer
Once you have installed Olive, try the automatic optimizer (olive auto-opt). In a single command, Olive will:
- Download the model from Hugging Face
- Capture the model structure into an ONNX graph and convert the weights into ONNX format.
- Optimize the ONNX graph (for example, fusion)
- Quantize the model weights into int4
The command to run automatic optimizer for the Llama-3.2-1B-Instruct model on CPU devices is:
olive auto-opt \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path optimized-model \
--device cpu \
--provider CPUExecutionProvider \
--precision int4 \
--use_model_builder True \
--log_level 1
Tip: If want to target:
- CUDA GPU, then update
--devicetogpuand--providertoCUDAExecutionProvider.- Windows DirectML, then update
--devicetogpuand--providertoDmlExecutionProvider.Olive will apply the optimizations specific to the device and provider.
With the auto-opt command, you can change the input model to one that is available on Hugging Face - for example, HuggingFaceTB/SmolLM-360M-Instruct - or a model that resides on local disk. It should be noted that the --trust_remote_code argument in olive auto-opt is only required for custom models in Hugging Face that are required to run code on your machine - for more details, read the Hugging Face documentation on trust_remote_code. Olive, will go through the same process of automatically converting (to ONNX), optimizing the graph and quantizing the weights.
🧪 Experimenting with different quantization algorithms
The Olive CLI allows you to experiment with many different quantization algorithms - such as AWQ, GPTQ, and QuaRot - and different implementations of those algorithms. For example, to Quantize Llama-3.2-1B-Instruct using Activation Aware Quantization (AWQ):
Note: Your computer will need a CUDA GPU device and associated drivers installed to run AWQ, GPTQ and QuaRot quantization. Also, you should install the AutoAWQ package using:
pip install autoawq
olive quantize \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--algorithm awq \
--output_path quantized-model \
--log_level 1
The quantize command will output a PyTorch model when using AWQ method, which you can convert to ONNX if you intend to use the model on the ONNX Runtime using:
olive capture-onnx-graph \
--model_name_or_path quantized-model/model \
--use_ort_genai True \
--log_level 1 \
🎚️ Finetuning
The Olive CLI also provides the tools to fine tune an AI Model on our own data for specific tasks using either LoRA or QLoRA. The following example will fine-tune Llama-3.2-1B-Instruct for phrase classification (given a phrase in English it will output a category for the phrase from joy/sad/fear/surprised).
olive finetune \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path models/llama3.2/ft \
--data_name xxyyzzz/phrase_classification \
--text_template "<|start_header_id|>user<|end_header_id|>\n{phrase}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n{tone}" \
--method qlora \
--max_steps 30 \
--log_level 1 \
The finetune command will output a Hugging Face PEFT adapter, which you can prepare for the ONNX runtime using:
# Step 1 - capture the ONNX graph of the base model and adapter
olive capture-onnx-graph \
--model_name_or_path models/llama3.2/ft/model \
--adapter_path models/llama3.2/ft/adapter \
--use_ort_genai \
--output_path models/llama3.2/onnx \
--log_level 1
# Step 2 - Extract adapter weights from ONNX model and store in separate file for ORT
olive generate-adapter \
--model_name_or_path models/llama3.2/onnx \
--output_path adapter-onnx \
--log_level 1
🤝 Inference your optimized AI models using the Generate API for ONNX Runtime
The following Python code creates a simple console-based chat interface that inferences your optimized model with the Generate API for ONNX runtime.
Tip: Other language bindings - such as C#, C/C++, Java - with more coming soon. For an up-to-date list, visit the Generate API for ONNX Runtime Github page
import onnxruntime_genai as og
import numpy as np
import os
model_folder = "optimized-model/model"
# Load the base model and tokenizer
model = og.Model(model_folder)
tokenizer = og.Tokenizer(model)
tokenizer_stream = tokenizer.create_stream()
# Set the max length to something sensible by default,
# since otherwise it will be set to the entire context length
search_options = {}
search_options['max_length'] = 200
search_options['past_present_share_buffer'] = False
chat_template = """<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
"""
text = input("Input: ")
# Keep asking for input phrases
while text != "exit":
if not text:
print("Error, input cannot be empty")
exit
# generate prompt (prompt template + input)
prompt = f'{chat_template.format(input=text)}'
# encode the prompt using the tokenizer
input_tokens = tokenizer.encode(prompt)
params = og.GeneratorParams(model)
params.set_search_options(**search_options)
params.input_ids = input_tokens
generator = og.Generator(model, params)
print("Output: ", end='', flush=True)
# stream the output
try:
while not generator.is_done():
generator.compute_logits()
generator.generate_next_token()
new_token = generator.get_next_tokens()[0]
print(tokenizer_stream.decode(new_token), end='', flush=True)
except KeyboardInterrupt:
print(" --control+c pressed, aborting generation--")
print()
text = input("Input: ")Conclusion
In this blog we demonstrated how you can compose models for the ONNX Rutime using the new Olive CLI, and then inference those models using the Generate API for ONNX Runtime. The Olive CLI commands execute a curated Olive workflow for you, meaning you continue to get all the following benefits:
- Reduce frustration and time of trial-and-error manual experimentation with different techniques for graph optimization, compression and quantization. Define your quality and performance constraints and let Olive automatically find the best model for you.
- 40+ built-in model optimization components covering cutting edge techniques in quantization, compression, graph optimization and finetuning.
- Supports creating models so they can be served using the Multi LoRA paradigm.
- Hugging Face and Azure AI Integration.
- Built-in caching mechanism to save costs and enhance team collaboration. As we shared in an earlier blog post, Olive also supports a shared cache.