Enhance team collaboration during AI model optimization with the Olive Shared Cache feature
By:
Xiaoyu Zhang, Devang Patel, Sam Kemp30TH OCTOBER, 2024
👋 Introduction
In the ever-evolving realm of machine learning, optimization stands as a crucial pillar for enhancing model performance, reducing latency, and cutting down costs. Enter Olive, a powerful tool designed to streamline the optimization process through its innovative shared cache feature.
Efficiency in machine learning not only relies on the effectiveness of algorithms but also on the efficiency of the processes involved. Olive’s shared cache feature – backed by Azure Storage - embodies this principle by seamlessly allowing intermediate models to be stored and reused within a team, avoiding redundant computations.
This blog post delves into how Olive’s shared cache feature can help you save time and costs, illustrated with practical examples.
Prerequisites
- An Azure Storage Account. For details on how to create an Azure Storage Account, read Create an Azure Storage Account.
- Once you have created your Azure Storage Account, you’ll need to create a storage container (a container organizes a set of blobs, similar to a directory in a file system). For more details on how to create a storage container, read Create a container.
🤝 Team collaboration during optimization process
User A begins the optimization process by employing Olive’s quantize command to optimize the Phi-3-mini-4k-instruct model using the AWQ algorithm. This step is marked by the following command line execution:
olive quantize \
--model_name_or_path Microsoft/Phi-3-mini-4k-instruct \
--algorithm awq \
--account_name {AZURE_STORAGE_ACCOUNT} \
--container_name {STORAGE_CONTAINER_NAME} \
--log_level 1
Note:
- The
--account_nameshould be set to your Azure Storage Account name.- The
--container_nameshould be set to the container name in the Azure Storage Account.
The optimization process generates a log that confirms the cache has been saved in a shared location in Azure:
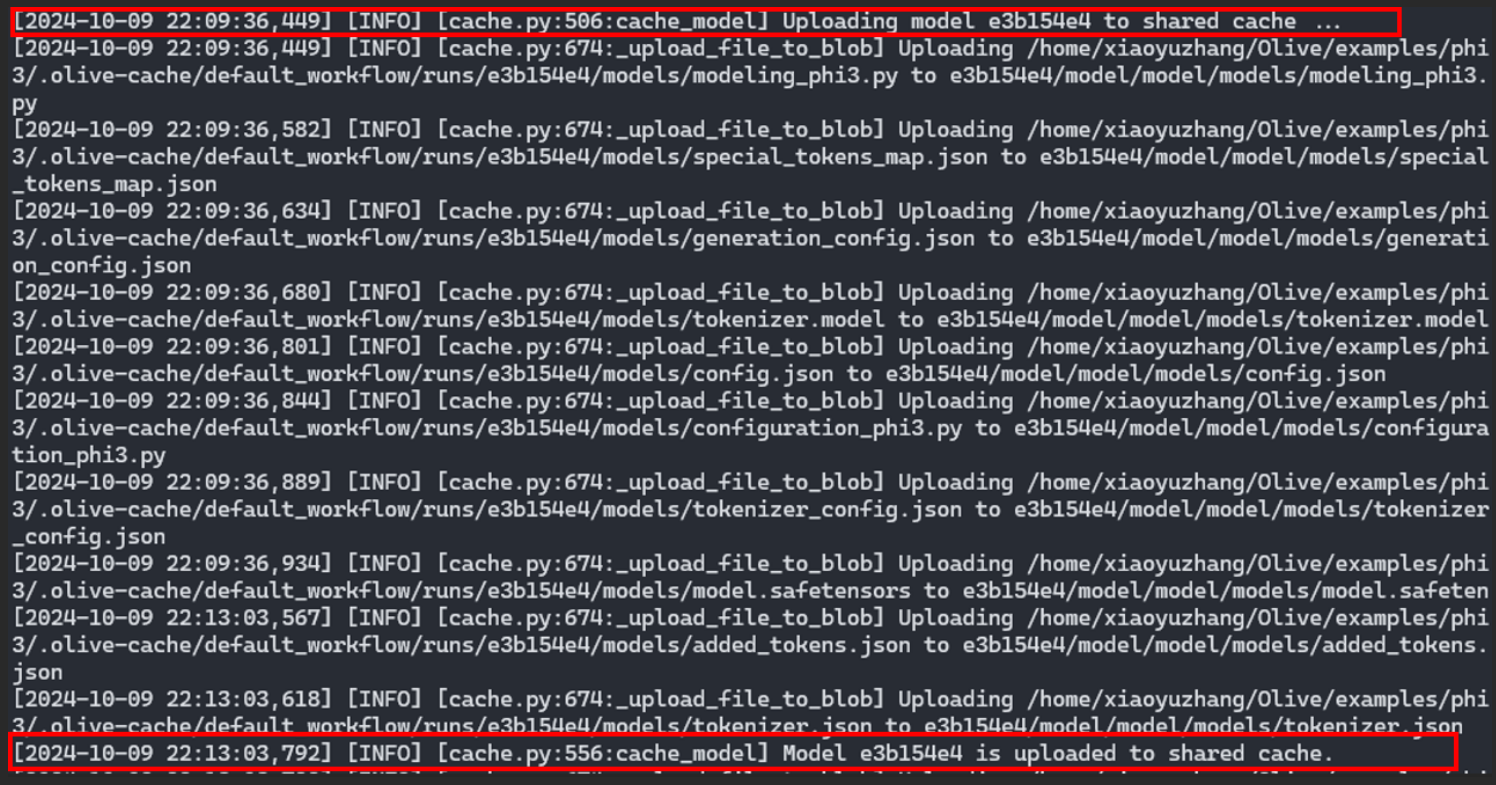 Olive log output from User A: The quantized model from User A's workflow is uploaded to the shared cache in the cloud.
Olive log output from User A: The quantized model from User A's workflow is uploaded to the shared cache in the cloud.This shared cache is a pivotal element, as it stores the optimized model, making it accessible for future use by other users or processes.
Leveraging the shared cache
User B, another active team member in the optimization project, reaps the benefits of User A’s efforts. By using the same quantize command to optimize the Phi-3-mini-4k-instruct with the AWQ algorithm, User B’s process is significantly expedited. The command is identical, and User B leverages the same Azure Storage account and container:
olive quantize \
--model_name_or_path Microsoft/Phi-3-mini-4k-instruct \
--algorithm awq \
--account_name {AZURE_STORAGE_ACCOUNT} \
--container_name {STORAGE_CONTAINER_NAME} \
--log_level 1
A critical part of this step is the following log output highlights the retrieval of the quantized model from the shared cache rather than re-computing the AWQ quantization.
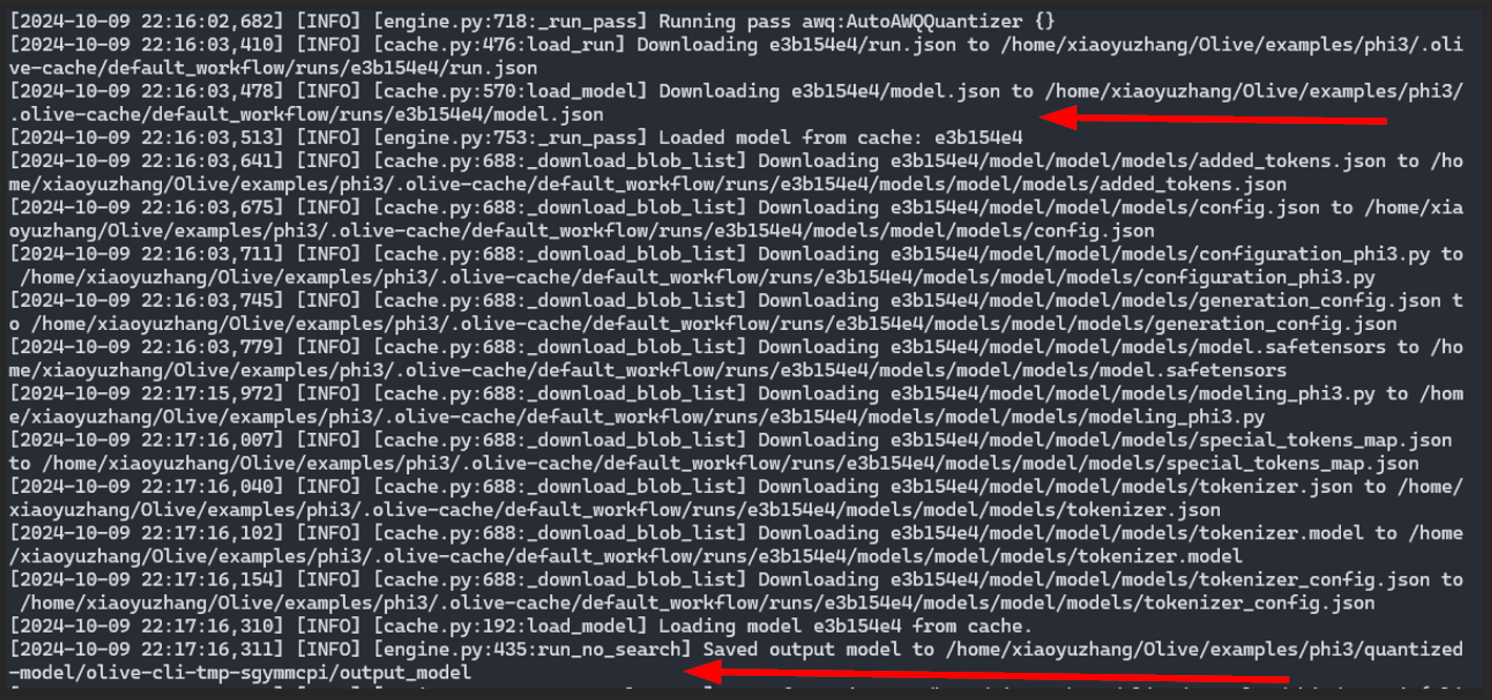 Olive log output from User B: The quantized model from User A's workflow is downloaded and consumed in User B's workflow without having to re-compute.
Olive log output from User B: The quantized model from User A's workflow is downloaded and consumed in User B's workflow without having to re-compute.This mechanism not only saves computational resources but also slashes the time required for the optimization. The shared cache in Azure serves as a repository of pre-optimized models, ready for reuse and thus enhancing efficiency.
🪄 Shared cache + Automatic optimizer
Optimization is not limited to quantization alone. Olive’s Automatic optimizer extends its capabilities by running further pre-processing and optimization tasks in a single command to find the best model in terms of quality and performance. Typical optimization tasks run in Automatic optimizer are:
- Downloading the model from Hugging Face
- Capture the model structure into an ONNX graph and convert the weights into ONNX format.
- Optimize the ONNX graph (for example, fusion, compression)
- Apply specific kernel optimizations for target hardware
- Quantize the model weights
User A leverages Automatic optimizer to optimize the Llama-3.2-1B-Instruct for CPU. The command line instruction for this task is:
olive auto-opt \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path optimized-model \
--device cpu \
--provider CPUExecutionProvider \
--precision int4 \
--account_name {AZURE_STORAGE_ACCOUNT} \
--container_name {STORAGE_CONTAINER_NAME} \
--log_level 1
For each task executed in the automatic optimizer - for example, model download, ONNX Conversion, ONNX graph optimization, Quantization, etc - the intermediate model will be stored in the shared cache for reuse on different hardware targets. For example, if later User B wants to optimize the same model for a different target (say, the GPU of a Windows device) they would execute the following command:
olive auto-opt \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path optimized-model \
--device gpu \
--provider DmlExecutionProvider \
--precision int4 \
--account_name {AZURE_STORAGE_ACCOUNT} \
--container_name {STORAGE_CONTAINER_NAME} \
--log_level 1
The common intermediate steps User A’s CPU optimization - such as ONNX conversion and ONNX graph optimization - will be reused, which will save User B time and cost.
This underscores Olive’s versatility, not only in optimizing different models but also in applying a variety of algorithms and exporters. The shared cache again plays a critical role by storing these optimized intermediate models for subsequent use.
➕ Benefits of the Olive shared cache feature
The examples above showcase Olive’s shared cache as a game-changer in model optimization. Here are the key benefits:
- Time Efficiency: By storing optimized models, the shared cache eliminates the need for repetitive optimizations, drastically reducing time consumption.
- Cost Reduction: Computational resources are expensive. By minimizing redundant processes, the shared cache cuts down on the associated costs, making machine learning more affordable.
- Resource Optimization: Efficient use of computational power leads to better resource management, ensuring that resources are available for other critical tasks.
- Collaboration: The shared cache fosters a collaborative environment where different users can benefit from each other’s optimization efforts, promoting knowledge sharing and teamwork.
Conclusion
By saving and reusing optimized models, Olive’s shared cache feature paves the way for a more efficient, cost-effective, and collaborative environment. As AI continues to grow and evolve, tools like Olive will be instrumental in driving innovation and efficiency. Whether you are a seasoned data scientist or a newcomer to the field, embracing Olive can significantly enhance your workflow. By reducing the time and costs associated with model optimization, you can focus on what truly matters: developing groundbreaking AI models that push the boundaries of what is possible. Embark on your optimization journey with Olive today and experience the future of machine learning efficiency.
⏭️ Try Olive
To try the quantization and Auto Optimizer commands with the shared-cache feature execute the following pip install:
pip install olive-ai[auto-opt,shared-cache] autoawqQuantizing a model using the AWQ algorithm requires a CUDA GPU device. If you only have access to a CPU device, and do not have an Azure subscription you can execute the automatic optimizer with a CPU and use local disk as the cache:
olive auto-opt \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path optimized-model \
--device cpu \
--provider CPUExecutionProvider \
--precision int4 \
--log_level 1