Phi-3 Small and Medium Models are now optimized with ONNX Runtime and DirectML
21ST MAY, 2024
We previously shared optimization support for Phi-3 mini. We now introduce optimized ONNX variants of the newly introduced Phi-3 models. The new Phi-3-Small and Phi-3-Medium outperform language models of the same size as well as those that are much larger. Phi-3-small beats GPT-3.5T across a variety of language, reasoning, coding and math benchmarks. The new models empower developers with a building block for generative AI applications which require strong reasoning, limited compute, and latency bound scenarios.
Phi-3-Medium is a 14B parameter language model. It is available in short-(4K) and long-(128K) context variants. You can now find the Phi-3-medium-4k-instruct-onnx and Phi-3-medium-128K-instruct-onnx optimized models with ONNX Runtime and DML on Huggingface! Check the Phi-3 Collection for the ONNX models.
We also have added support for Phi-3 Small models for CUDA capable Nvidia GPUs, other variants coming soon. We have added Phi-3 Small models for CUDA capable Nvidia GPUs, other variants coming soon. We also have added support for Phi-3 Small models for CUDA capable Nvidia GPUs, other variants coming soon. This includes support for Block Sparse kernel in the newly released ONNX Runtime 1.18 release via in ONNX Runtime generate() API.
ONNXRuntime 1.18 adds new features like improved 4bit quantization support, improved MultiheadAttention performance on CPU, and ONNX Runtime generate() API enhancements to enable easier and efficient run across devices.
We are also happy to share that the new optimized ONNX Phi-3-mini for web deployment is available now. You can run Phi3-mini-4K entirely in the browser! Please check out the model here. What’s more, we now have updated the optimized ONNX version for CPU and mobile with even better performance. And don’t miss this blog about how to run Phi-3 on your phone and in the browser.
How to run Phi-3-Medium and Small with ONNX Runtime
You can utilize the ONNX Runtime generate() API to run these models seamlessly. You can see the detailed instructions here. You can also run the chat app locally.
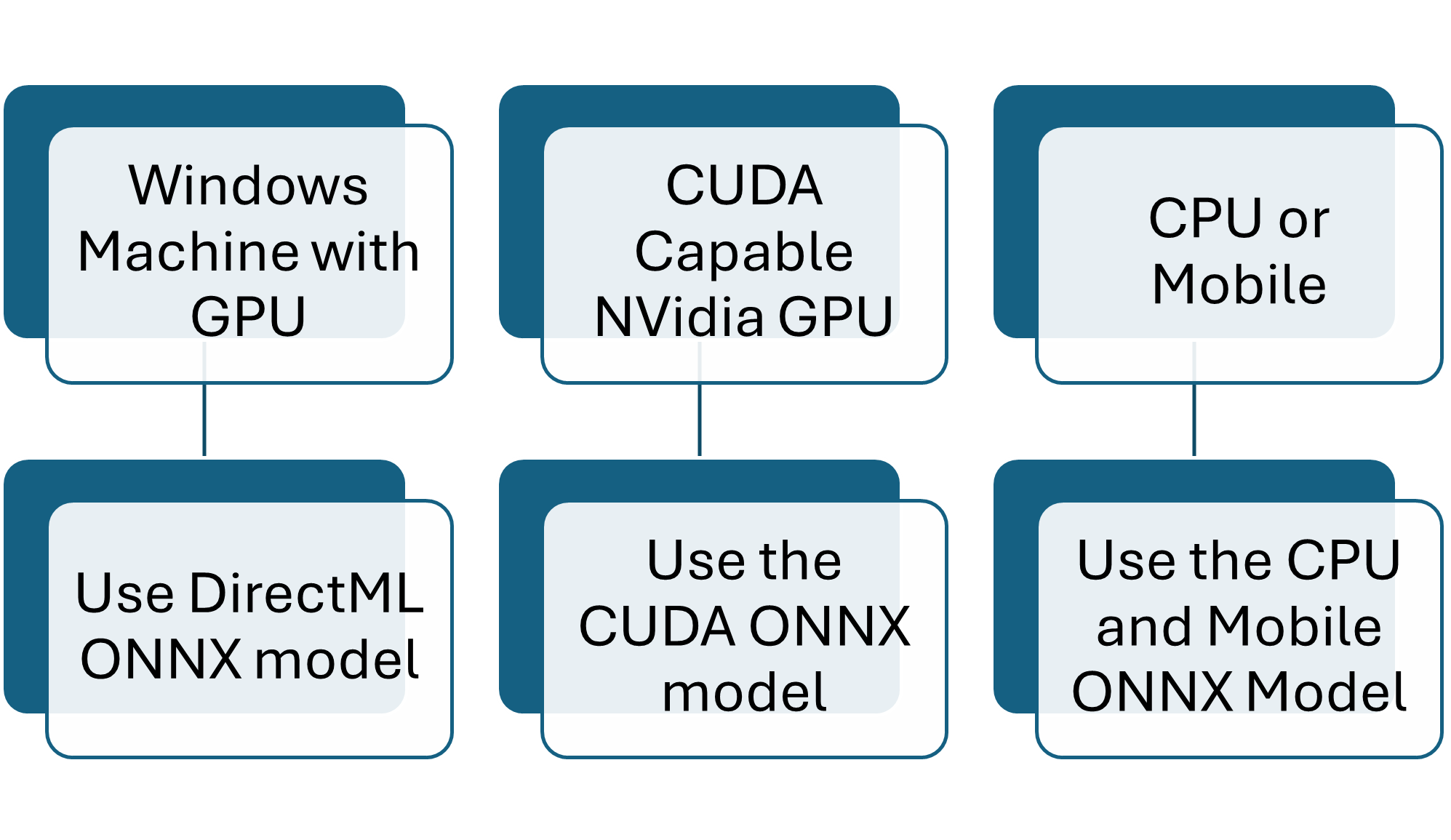
Only one package and model combination is required based on your hardware.
3 easy steps to run
- Download the model
- Install the generate() API
- Run the model with phi3-qa.py
Only execute the steps needed for your hardware.
Optimized for your Platform
Phi-3 Small 8K ONNX Model:
Phi-3 Medium 4k ONNX Models:
- microsoft/Phi-3-medium-4k-instruct-onnx-cpu
- microsoft/Phi-3-medium-4k-instruct-onnx-cuda
- microsoft/Phi-3-medium-4k-instruct-onnx-directml
Phi-3 Medium 128k ONNX Models:
Performance
The ONNX Runtime models can run up to 10X faster than the PyTorch variants. The Token Generation Throughput in tokens/sec is listed below for different variants.
| Model | Batch Size, Prompt Length | Model Variant | Token Generation Throughput (tokens/sec) |
|---|---|---|---|
| Phi-3 Medium 4K | |||
| Phi-3 Medium 4K 14B ONNX CUDA | 1, 16 | FP16 CUDA GPU with ONNX Runtime | 47.32 |
| Phi-3 Medium 4K 14B ONNX CUDA | 16, 64 | FP16 CUDA GPU with ONNX Runtime | 698.22 |
| Phi-3 Medium 4K 14B ONNX CUDA | 1, 16 | INT4 RTN CUDA GPU with ONNX Runtime | 115.68 |
| Phi-3 Medium 4K 14B ONNX CUDA | 16, 64 | INT4 RTN CUDA GPU with ONNX Runtime | 339.45 |
| Phi-3 Medium 4K 14B ONNX DML | 1, 16 | DML INT4 AWQ with ONNX Runtime | 72.39 |
| Phi-3 Medium 4K 14B ONNX CPU | 16, 64 | INT4 RTN CPU with ONNX Runtime | 20.77 |
| Phi-3 Medium 128K | |||
| Phi-3 Medium 128K 14B ONNX CUDA | 1, 16 | FP16 CUDA GPU with ONNX Runtime | 46.27 |
| Phi-3 Medium 128K 14B ONNX CUDA | 16, 64 | FP16 CUDA GPU with ONNX Runtime | 662.23 |
| Phi-3 Medium 128K 14B ONNX CUDA | 1, 16 | INT4 RTN CUDA GPU with ONNX Runtime | 108.59 |
| Phi-3 Medium 128K 14B ONNX CUDA | 16, 64 | INT4 RTN CUDA GPU with ONNX Runtime | 332.57 |
| Phi-3 Medium 128K 14B ONNX DML | 1, 16 | DML INT4 AWQ with ONNX Runtime | 72.26 |
| Model | Batch Size, Prompt Length | Model Variant | Token Generation Throughput (tokens/sec) |
|---|---|---|---|
| Phi-3 Small 8k | |||
| Phi-3 Small 8K 7B ONNX CUDA | 1, 16 | FP16 CUDA GPU with ONNX Runtime | 74.62 |
| Phi-3 Small 8K 7B ONNX CUDA | 16, 64 | FP16 CUDA GPU with ONNX Runtime | 1036.93 |
| Phi-3 Small 8K 7B ONNX CUDA | 1, 16 | INT4 RTN CUDA GPU with ONNX Runtime | 140.68 |
| Phi-3 Small 8K 7B ONNX CUDA | 16, 64 | INT4 RTN CUDA GPU with ONNX Runtime | 582.07 |
| Phi-3 Small 128k | |||
| Phi-3 Small 128K 7B ONNX CUDA | 1, 16 | FP16 CUDA GPU with ONNX Runtime | 68.26 |
| Phi-3 Small 128K 7B ONNX CUDA | 16, 64 | FP16 CUDA GPU with ONNX Runtime | 577.41 |
| Phi-3 Small 128K 7B ONNX CUDA | 1, 16 | INT4 RTN CUDA GPU with ONNX Runtime | 73.60 |
| Phi-3 Small 128K 7B ONNX CUDA | 16, 64 | INT4 RTN CUDA GPU with ONNX Runtime | 1008.35 |
Devices:
- CUDA: A100 GPU, SKU: Standard_ND96amsr_A100_v4
- DML: Nvidia GeForce RTX 4080 (Dedicated Mem 16GB/Shared Mem 24GB)
- CPU: Intel(R) Core(TM) i9-10920X CPU @ 3.50GHz
Packages:
- onnxruntime-gpu: 1.18.0
Get started today
To experience optimized Phi-3 for yourself, you can now easily run these models using ONNX Runtime generate() API instructions. To learn more, join us at ONNX Runtime, DML, and Phi-3 sessions at Build!