ONNX Runtime supports Phi-3 mini models across platforms and devices
22ND APRIL, 2024
You can now run Microsoft’s latest home-grown Phi-3 models across a huge range of devices and platforms thanks to ONNX Runtime and DirectML. Today we’re proud to announce day 1 support for both flavors of Phi-3, phi3-mini-4k-instruct and phi3-mini-128k-instruct. The optimized ONNX models are available at phi3-mini-4k-instruct-onnx and phi3-mini-128k-instruct-onnx.
Many language models are too large to run locally on most devices, but Phi-3 represents a significant exception to this rule: this small but mighty suite of models achieves comparable performance to models 10 times larger! Phi-3 Mini is also the first model in its weight class to support long contexts of up to 128K tokens. To learn more about how Microsoft’s strategic data curation and innovative scaling achieved these remarkable results, see here.
You can easily get started with Phi-3 with our newly introduced ONNX runtime Generate() API, found here!
DirectML and ONNX Runtime scales Phi-3 Mini on Windows
By itself, Phi-3 is already small enough to run on many Windows devices, but why stop there? Making Phi-3 even smaller with quantization would dramatically expand the model’s reach on Windows, but not all quantization techniques are created equal. We wanted to ensure scalability while also maintaining model accuracy.
Activation-Aware Quantization (AWQ) to quantize Phi-3 Mini lets us reap the memory savings from quantization with only a minimal impact on accuracy. AWQ achieves this by identifying the top 1% of salient weights that are necessary for maintaining model accuracy and quantizing the remaining 99% of weights. This leads to much less accuracy loss from quantization with AWQ compared to many other quantization techniques. For more on AWQ, see here.
Every GPU that supports DirectX 12 on Windows can run DirectML, regardless of whether it’s an AMD, Intel, or NVIDIA GPU. DirectML and ONNX Runtime now support INT4 AWQ, which means developers can now run and deploy this quantized version of Phi-3 across hundreds of millions of Windows devices!
We’re working with our hardware vendor partners to provide driver updates that will further improve performance in the coming weeks.
See below for dedicated performance numbers.
ONNX Runtime for Mobile
In addition to supporting both Phi-3 Mini models on Windows, ONNX Runtime can help run these models on other client devices including Mobile and Mac CPUs, making it a truly cross-platform framework. ONNX Runtime also supports quantization techniques like RTN to enable these models to run across many different types of hardware.
ONNX Runtime Mobile empowers developers to perform on-device inference with AI models on mobile and edge devices. By removing client-server communications, ORT Mobile provides privacy protection and has zero cost. Using RTN INT4 quantization, we significantly reduce the size of the state-of-the-art Phi-3 Mini models and can run both on a Samsung Galaxy S21 at a moderate speed. When applying RTN INT4 quantization, there is a tuning parameter for the int4 accuracy level. This parameter specifies the minimum accuracy level required for the activation of MatMul in int4 quantization, balancing performance and accuracy trade-offs. Two versions of RTN quantized models have been released with int4_accuracy_level=1, optimized for accuracy, and int4_accuracy_level=4, optimized for performance. If you prefer better performance with a slight trade-off in accuracy, we recommend using the model with int4_accuracy_level=4.
ONNX Runtime for Server Scenarios
For Linux developers and beyond, ONNX Runtime with CUDA is a great solution that supports a wide range of NVIDIA GPUs, including both consumer and data center GPUs. Phi-3 Mini-128K-Instruct performs better for ONNX Runtime with CUDA than PyTorch for all batch size, prompt length combinations.
For FP16 CUDA and INT4 CUDA, Phi-3 Mini-128K-Instruct with ORT performs up to 5X faster and up to 9X faster than PyTorch, respectively. Phi-3 Mini-128K-Instruct is currently not supported by Llama.cpp.
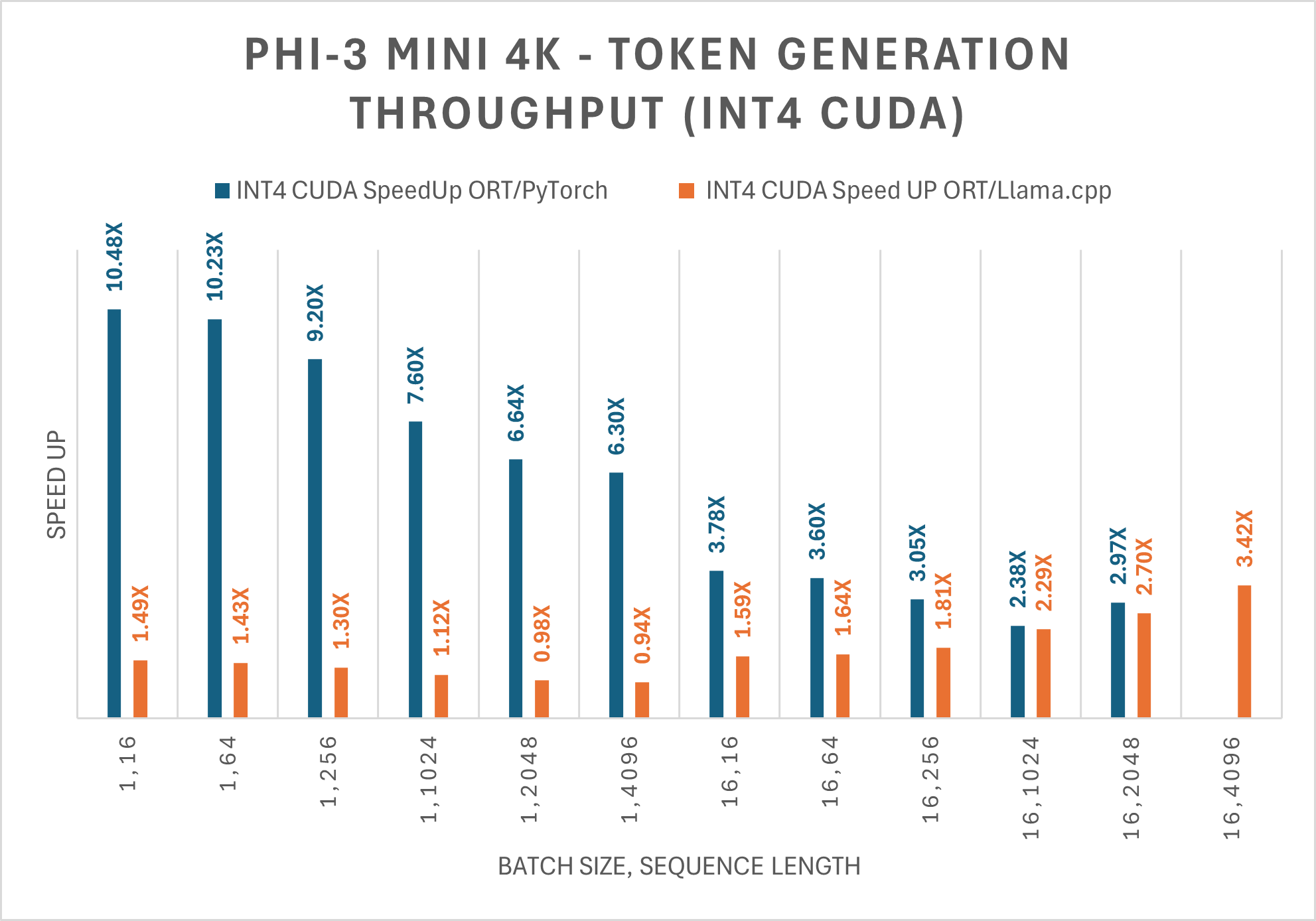
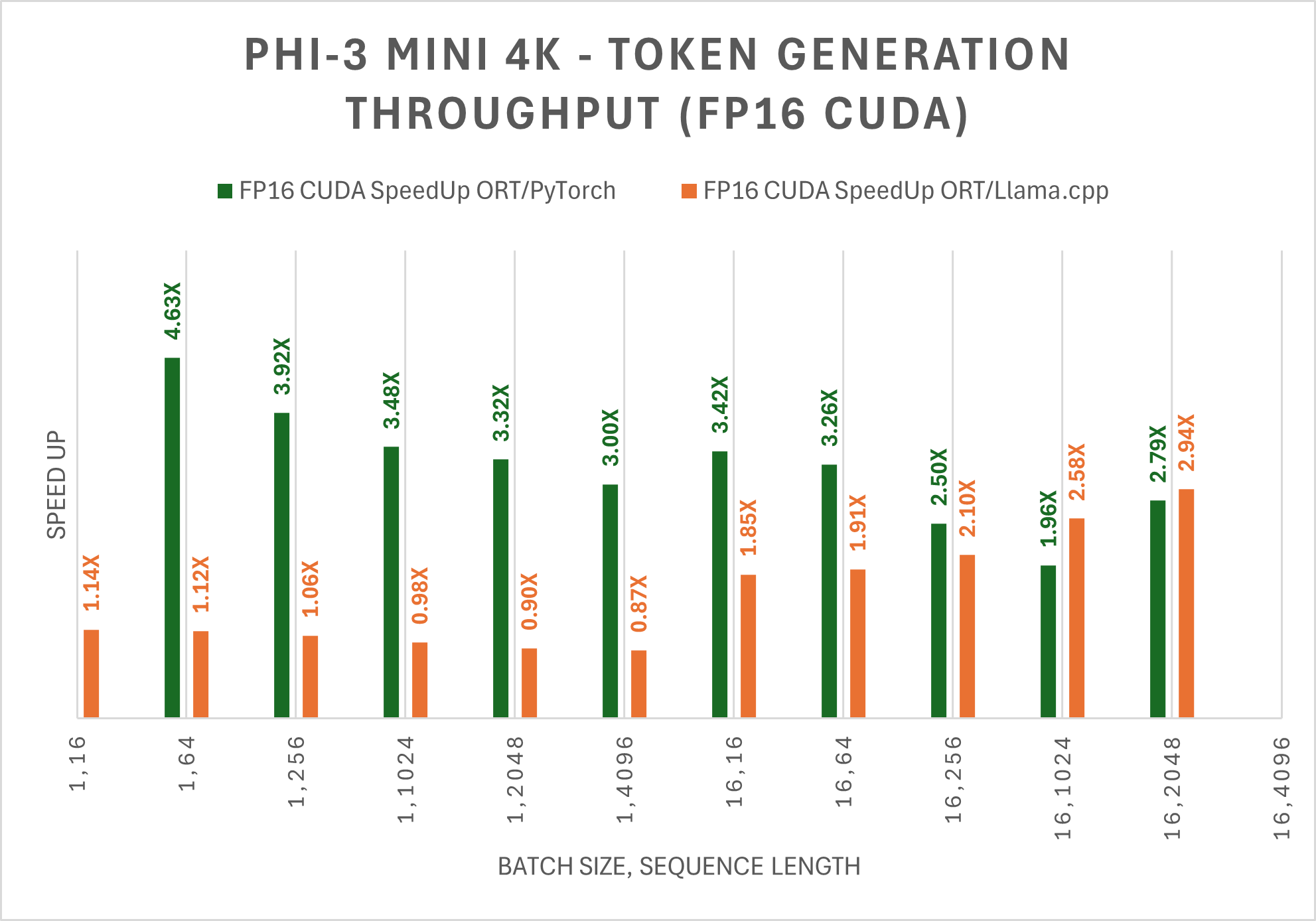
For FP16 and INT4 CUDA, Phi-3 Mini-4K-Instruct with ORT performs up to 5X faster and up to 10X faster than PyTorch, respectively. Phi-3 Mini-4K-Instruct is also up to 3X faster than Llama.cpp for large sequence lengths.
Whether it’s Windows, Linux, Android, or Mac, there’s a path to infer models efficiently with ONNX Runtime!
Try the ONNX Runtime Generate() API
We are pleased to announce our new Generate() API, which makes it easier to run the Phi-3 models across a range of devices, platforms, and EP backends by wrapping several aspects of generative AI inferencing. The Generate() API makes it easy to drag and drop LLMs straight into your app. To run the early version of these models with ONNX, follow the steps here.
Example:
python model-qa.py -m /YourModelPath/onnx/cpu_and_mobile/phi-3-mini-4k-instruct-int4-cpu -k 40 -p 0.95 -t 0.8 -r 1.0
Input: <user> Tell me a joke <end>
Output: <assistant> Why don't scientists trust atoms?
Because they make up everything!
This joke plays on the double meaning of "make up." In science, atoms are the fundamental building blocks of matter,
literally making up everything. However, in a colloquial sense, "to make up" can mean to fabricate or lie, hence the humor. <end>
Please watch this space for more updates on AMD, and additional optimization with ORT 1.18.
Performance Metrics
DirectML:
DirectML lets developers not only achieve great performance but also deploy models across the entire Windows ecosystem with support from AMD, Intel and NVIDIA. Best of all, AWQ means that developers get this scale while also maintaining high model accuracy.
Stay tuned for additional performance improvements in the coming weeks thanks to optimized drivers from our hardware partners and additional updates to the ONNX Generate() API.
| Prompt Length | Generation Length | Wall Clock tokens/s |
|---|---|---|
| 16 | 256 | 266.65 |
| 16 | 512 | 251.63 |
| 16 | 1024 | 238.87 |
| 16 | 2048 | 217.5 |
| 32 | 256 | 278.53 |
| 32 | 512 | 259.73 |
| 32 | 1024 | 241.72 |
| 32 | 2048 | 219.3 |
| 64 | 256 | 308.26 |
| 64 | 512 | 272.47 |
| 64 | 1024 | 245.67 |
| 64 | 2048 | 220.55 |
CUDA:
The table below shows improvement on the average throughput of the first 256 tokens generated (tps) for the Phi-3 Mini 128K Instruct ONNX model. The comparisons are for FP16 and INT4 precisions on CUDA, as measured on 1 A100 80GB GPU (SKU: Standard_ND96amsr_A100_v4).
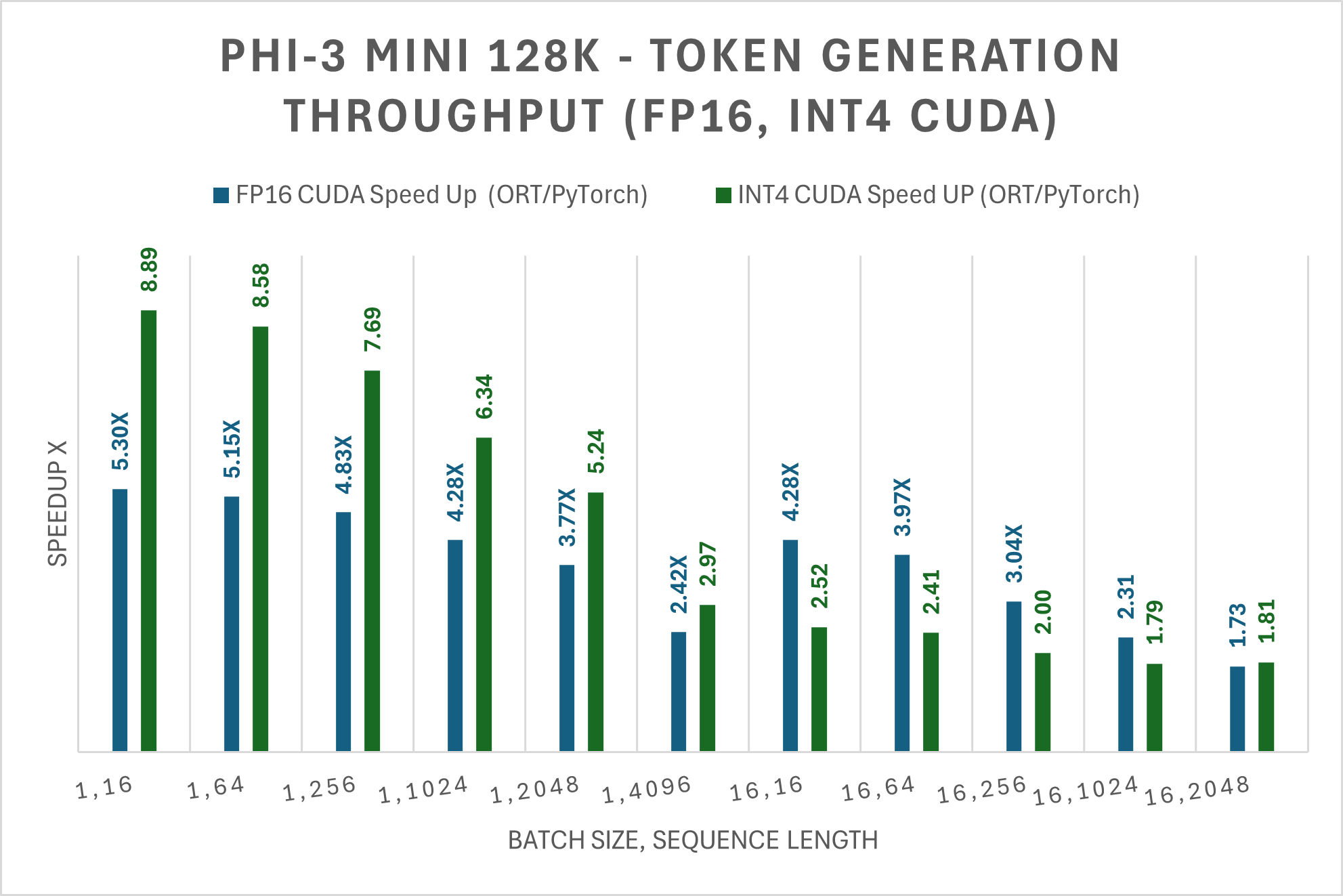 Note: PyTorch Compile and Llama.cpp do not currently support the Phi-3 Mini 128K instruct model.
Note: PyTorch Compile and Llama.cpp do not currently support the Phi-3 Mini 128K instruct model.The table below shows improvement on the average throughput of the first 256 tokens generated (tps) for Phi-3 Mini 4K Instruct ONNX model. The comparisons are for FP16 and INT4 precisions on CUDA, as measured on 1 A100 80GB GPU (SKU: Standard_ND96amsr_A100_v4).
Performance is improved across CPU and other devices as well.
Safety
Safety metrics and RAI align with the base Phi-3 models. See here for more details.
Try ONNX Runtime for Phi3
This blog post introduces how ONNX Runtime and DirectML optimize the Phi-3 model. We’ve included instructions for running Phi-3 across Windows and other platforms, as well as early benchmarking results. Further improvements and perf optimizations are under way, so stay tuned for the ONNX Runtime 1.18 release in early May!
We encourage you to try out Phi-3 and share your feedback in the ONNX Runtime GitHub repository!