Accelerating LLaMA-2 Inference with ONNX Runtime
By: Kunal Vaishnavi and Parinita Rahi
14TH NOVEMBER, 2023 (Updated 22nd November)
Interested in running Llama2 faster? Let us explore how ONNX Runtime can propel your Llama2 variants for faster inference!
You can now experience significant inference gains—up to 3.8X faster—for the 7B, 13B, and 70B models, thanks to state-of-the-art fusion and kernel optimizations with ONNX Runtime. This blog details performance enhancements, dives into ONNX Runtime fusion optimizations, multi-GPU inferencing support, and guides you on how to leverage the cross-platform prowess of ONNX Runtime for seamless inferencing across platforms. This is the first in a series of upcoming blogs that will cover additional aspects for efficient memory usage with ONNX Runtime quantization updates, and cross-platform usage scenarios.
Background: Llama2 and Microsoft
Llama2 is a state-of-the-art open source LLM from Meta ranging in scale from 7B to 70B parameters (7B, 13B, 70B). Microsoft and Meta announced their AI on Azure and Windows collaboration in July 2023. As part of the announcement, Llama2 was added to the Azure AI model catalog, which serves as a hub of foundation models that empower developers and machine learning (ML) professionals to easily discover, evaluate, customize, and deploy pre-built large AI models at scale.
ONNX Runtime allows users to easily integrate the power of this generative AI model into your apps and services with improved optimizations that yield faster inferencing speeds and lower your costs.
Faster Inferencing with New ONNX Runtime Optimizations
As part of the new 1.16.2 release, ONNX Runtime now has several built-in optimizations for Llama2, including graph fusions and kernel optimizations. The inference speedups, when compared to Hugging Face (HF) variants of Llama2 in PyTorch compile mode for prompt latency of CUDA FP16, are mentioned below. The end-to-end throughput or wall-clock throughput shown below is defined as batch size * (prompt length + token generation length) / wall-clock latency where wall-clock latency = the latency from running end-to-end and token generation length = 256 generated tokens. The E2E throughput is 2.4X more (13B) and 1.8X more (7B) when compared to PyTorch compile. For higher batch size, sequence length pairs such as (16, 2048), PyTorch eager times out, while ORT shows better performance than compile mode.
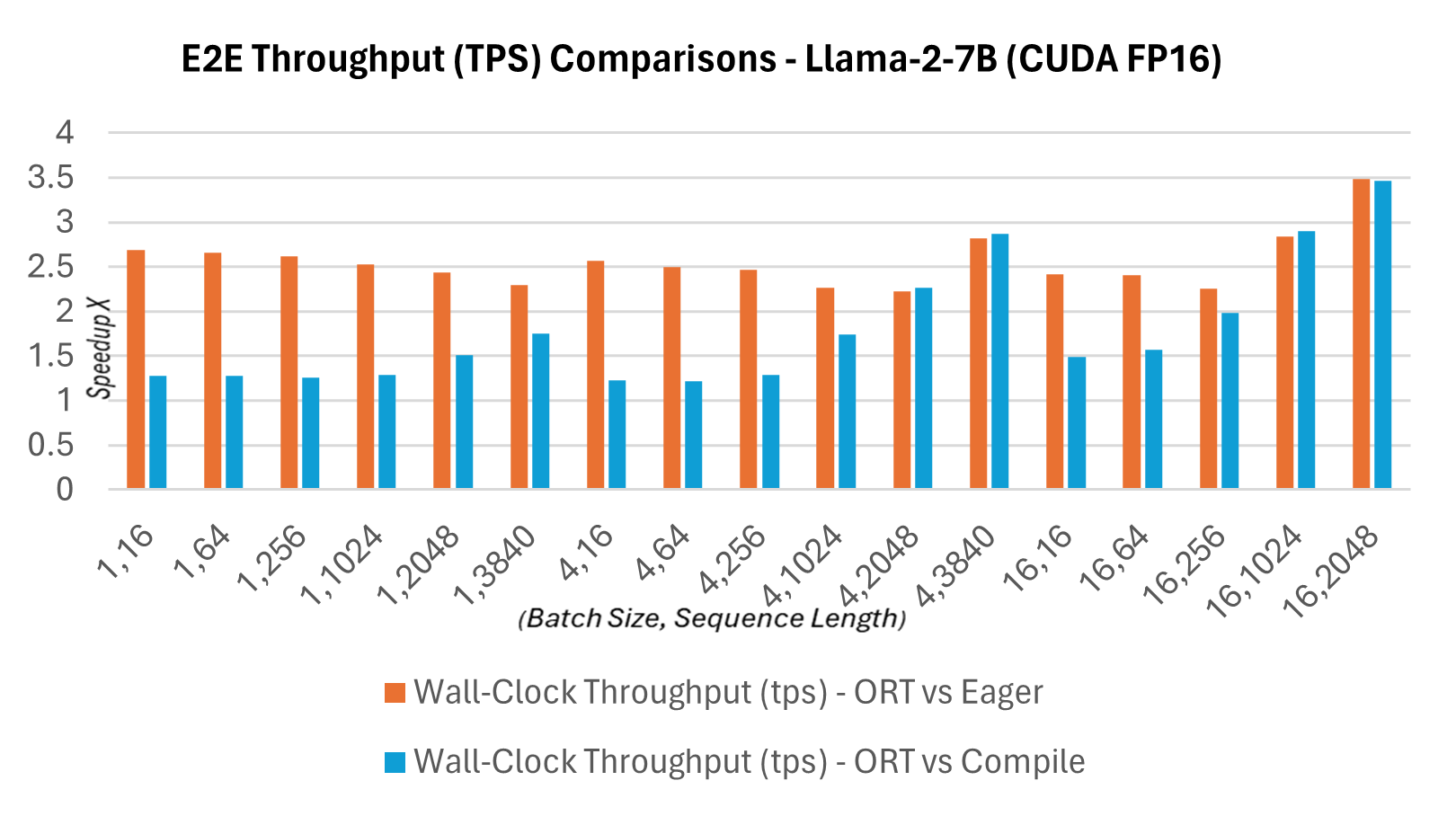
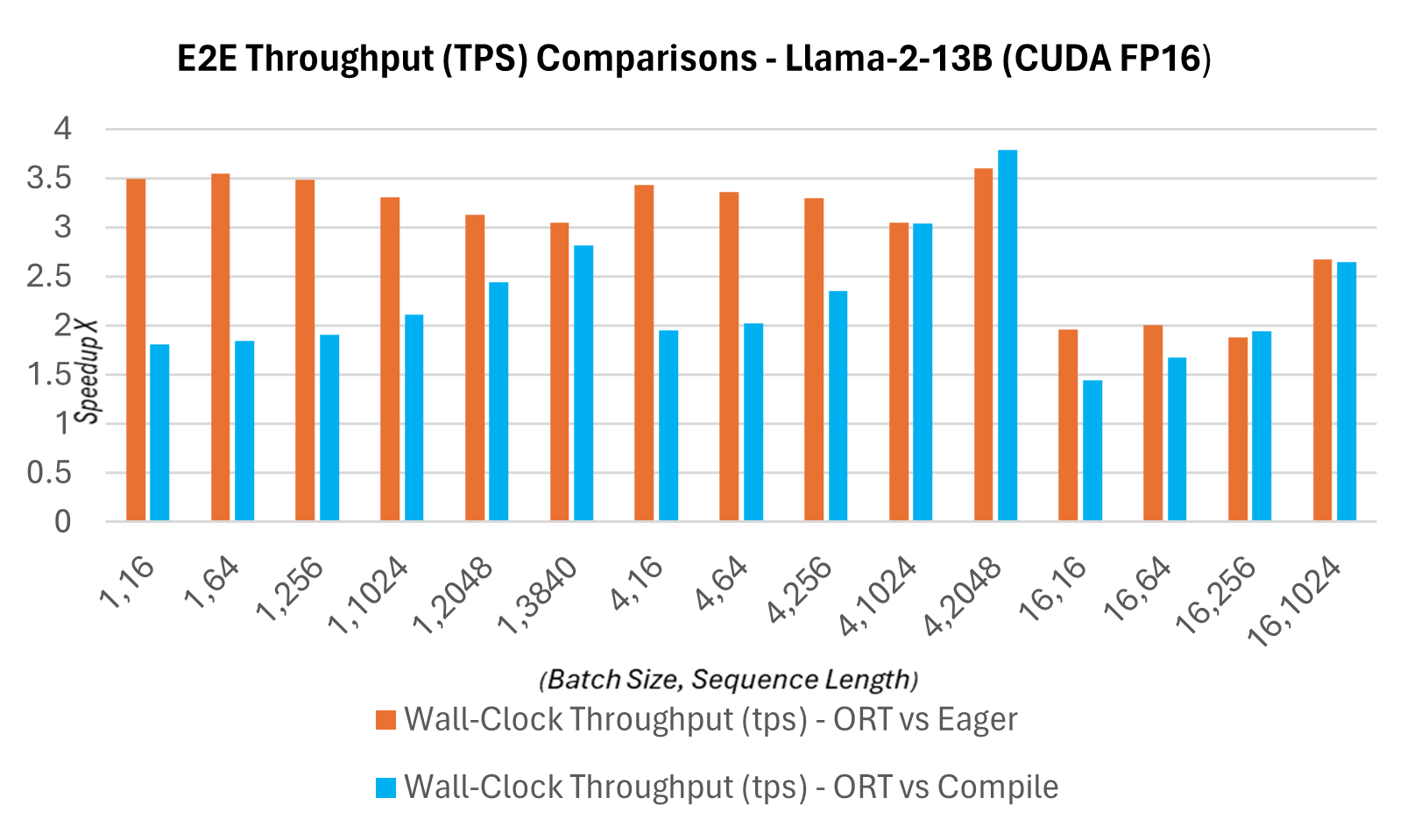
Latency and Throughput
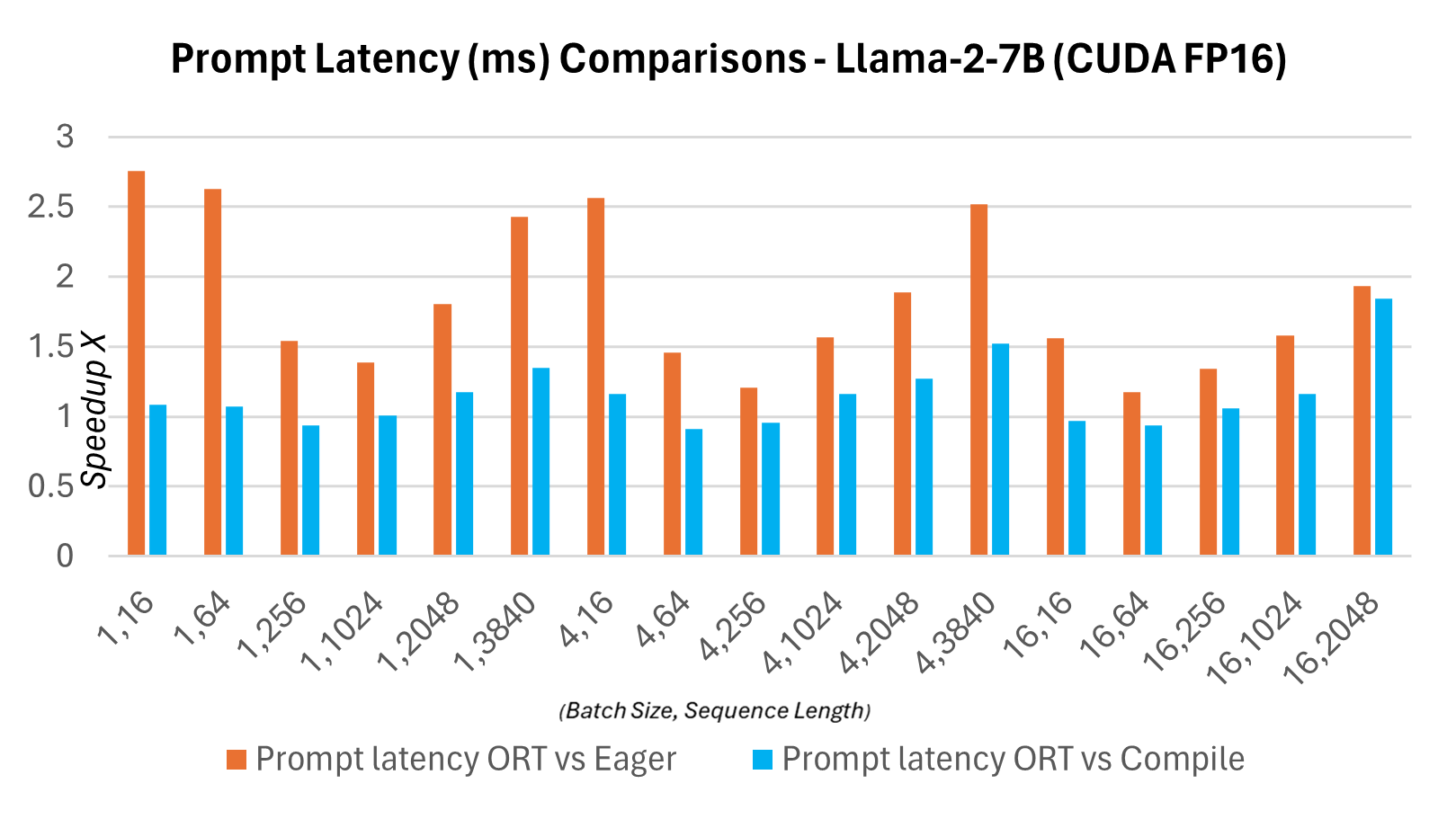
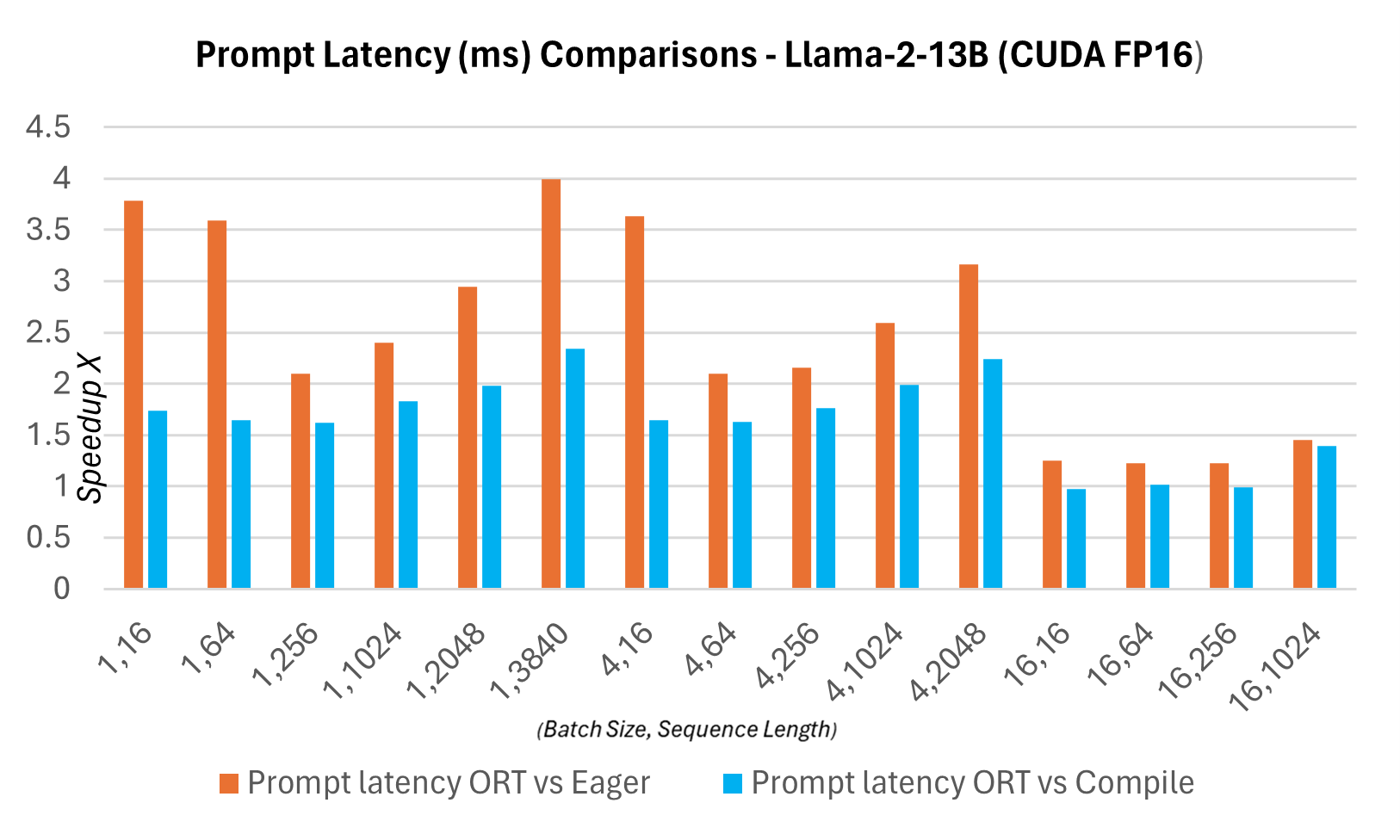
The graphs below show latency comparisons between the ONNX Runtime and PyTorch variants of the Llama2 7B model on CUDA FP16. Latency here is defined as the time it takes to complete one pass through the model to produce the logits and synchronize the outputs.
Token generation throughput below is the average throughput of the first 256 tokens generated. We see up to ~1.3X (7B) and ~1.5X (13B) gains in token generation throughput when compared to PyTorch compile mode.
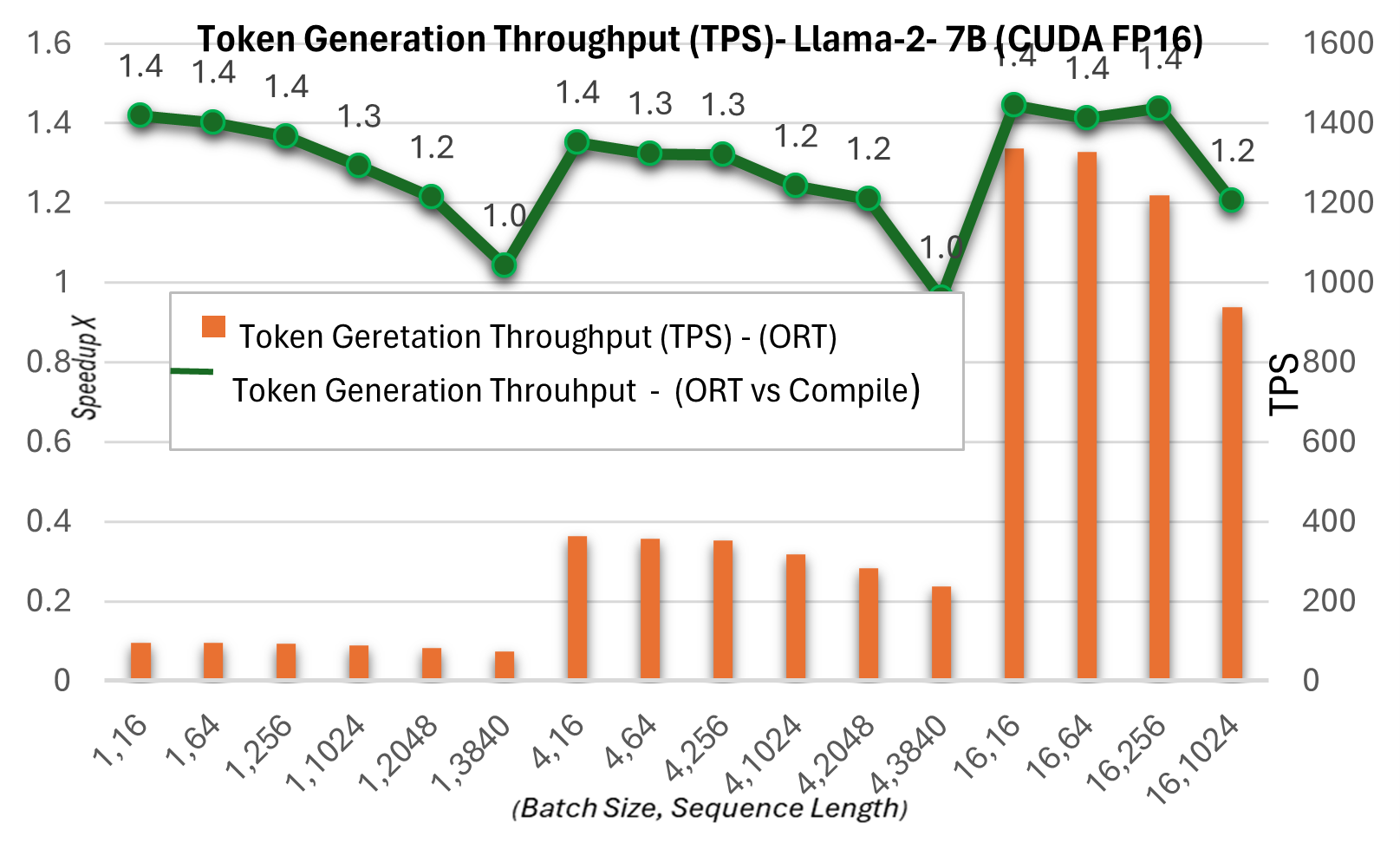
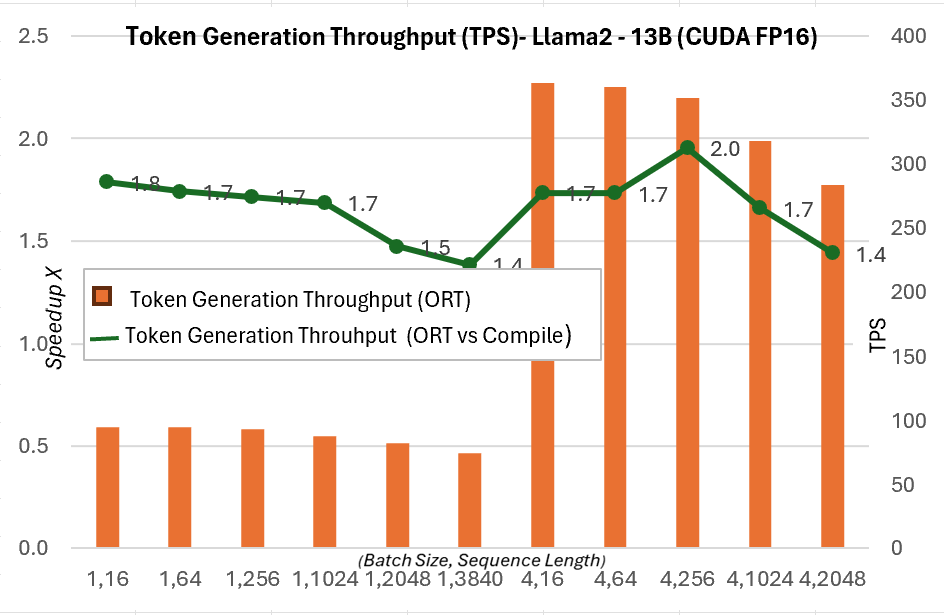
More details on these metrics can be found here.
ONNX Runtime with Multi-GPU Inference
ONNX Runtime supports multi-GPU inference to enable serving large models. Even in FP16 precision, the LLaMA-2 70B model requires 140GB. Loading the model requires multiple GPUs for inference, even with a powerful NVIDIA A100 80GB GPU.
ONNX Runtime applied Megatron-LM Tensor Parallelism on the 70B model to split the original model weight onto different GPUs. Megatron sharding on the 70B model shards the PyTorch model with FP16 precision into 4 partitions, converts each partition into ONNX format, and then applies a new ONNX Runtime graph fusion on the converted ONNX model. The 70B model has ~30 tokens per second throughput for token generation at batch size 1, and end-to-end throughput starts at 30 tps for smaller sequence lengths with these optimizations. You can find additional example scripts here.
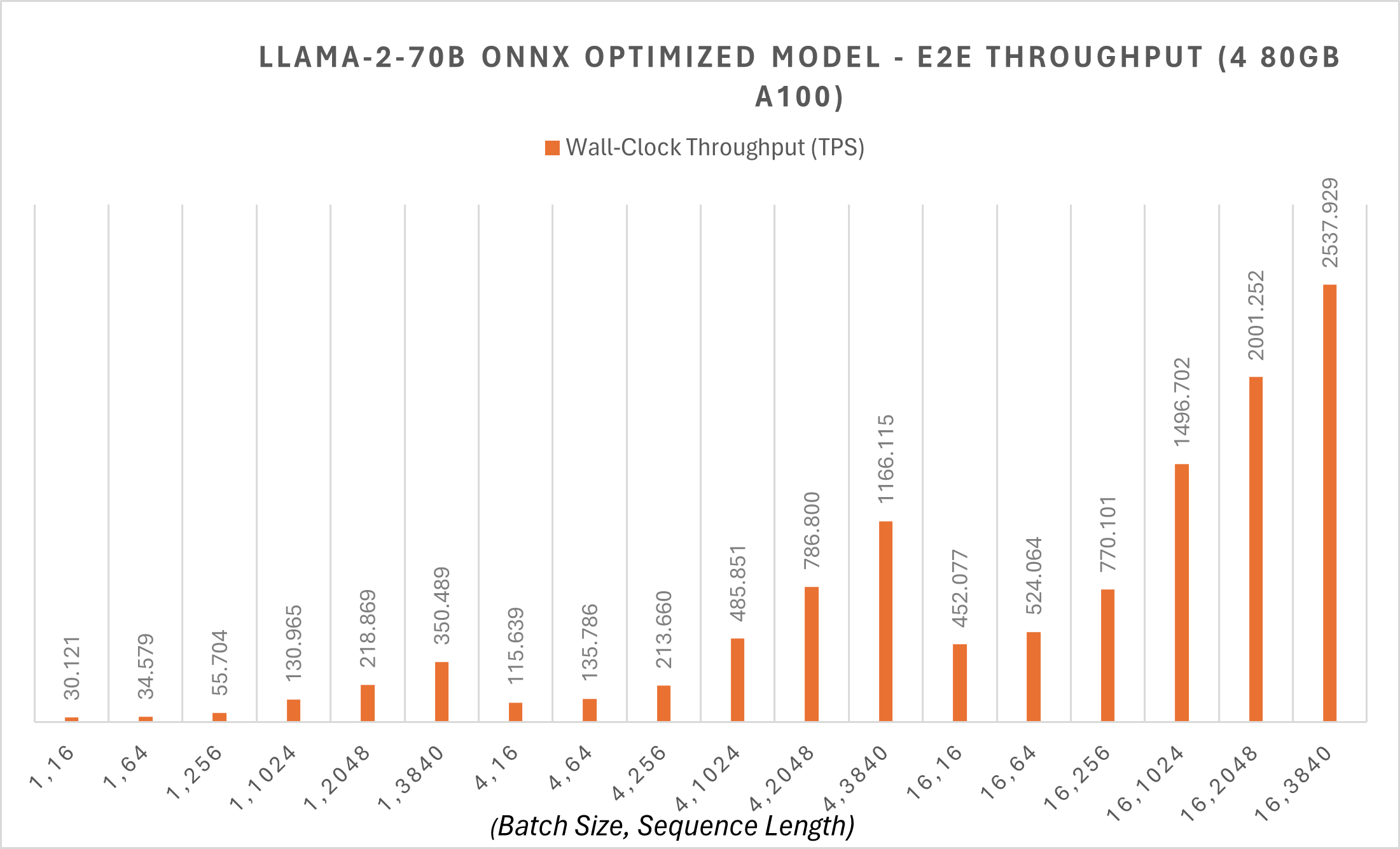
ONNX Runtime Optimizations

The techniques that ONNX Runtime uses for optimizations, such as graph fusions, are applicable to state-of-the-art models. As these models become more complex, the techniques used to apply the graph fusions are adapted to accommodate the extra complexity. For example, instead of manually matching fusion patterns in the graph, ONNX Runtime now supports automated pattern matching. Rather than detect large subgraphs by hand and match the many paths they form, fusion opportunities can instead be identified by exporting a large module as a function and then pattern matching against a function's spec.

As a concrete example, Figure 6 is an example of the nodes that comprise rotary embedding computations. Pattern matching against this subgraph is cumbersome because of the number of paths to verify. By exporting this as a function, the parent view of the graph will only show the inputs and outputs and represent all these nodes as a single operator.
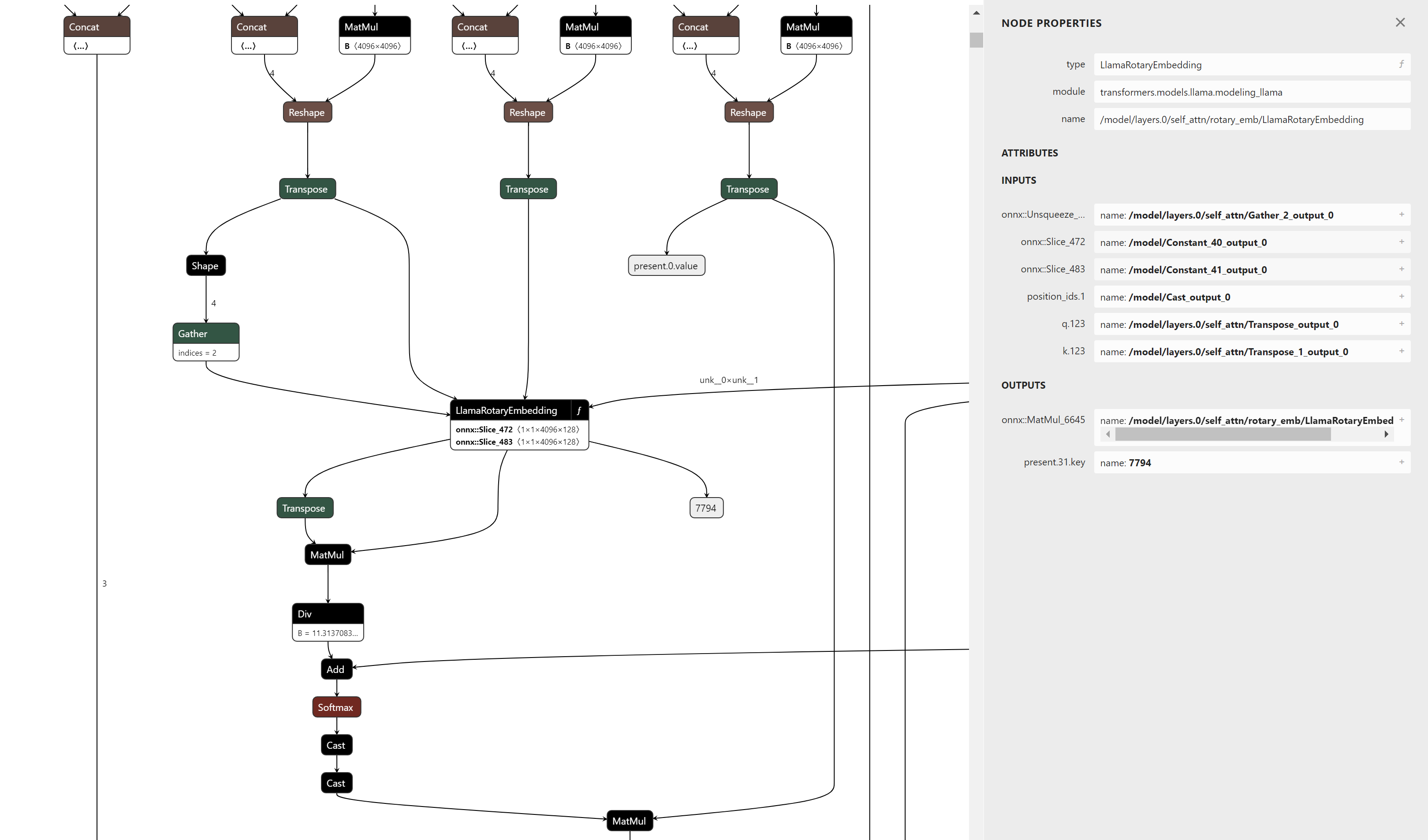
This approach makes it easier to maintain and support future versions of the rotary embedding computations because the pattern matching is only dependent on the operator's inputs and outputs instead of its internal semantic representation. It also allows other existing implementations of rotary embeddings in similar models such as GPT-NeoX, Falcon, Mistral, Zephyr, etc. to be pattern matched and fused with minimal or no changes.
ONNX Runtime also adds support for the GroupQueryAttention (GQA) operator, which leverages the new Flash Attention V2 algorithm and its optimized kernels to efficiently compute attention. The GQA operator supports past-present buffer sharing between the past key/value cache (past KV cache) and the present key/value cache (present KV cache). By binding the present KV caches to the past KV caches, there is no need to allocate separate on-device memory for both caches. Instead, the past KV caches can be pre-allocated with enough on-device memory so that no new on-device memory needs to be requested during inference. This reduces memory usage when the KV caches become large during compute-intensive workloads and lowers latency by eliminating on-device memory allocation requests. The past-present buffer sharing can be enabled or disabled without needing to change the ONNX model, allowing greater flexibility for end users to decide which approach is best for them.
In addition to these fusions and kernel optimizations, ONNX Runtime reduces the model’s memory usage. Besides quantization improvements (which will be covered in a future post), ONNX Runtime compresses the size of the cosine and sine caches used in each of the rotary embeddings by 50%. The compute kernels in ONNX Runtime that run the rotary embedding computations can then recognize this format and use their parallelized implementations to calculate the rotary embeddings more efficiently with less memory usage. The rotary embedding compute kernels also support interleaved and non-interleaved formats to support both the Microsoft version of LLaMA-2 and the Hugging Face version of LLaMA-2 respectively while sharing the same calculations.
The optimizations work for the Hugging Face versions (models ending with -hf) and the Microsoft versions. You can download the optimized HF versions from Microsoft's LLaMA-2 ONNX repository. Stay tuned for newer Microsoft versions coming soon!
Optimize your own model using Olive
Olive is a hardware-aware model optimization tool that incorporates advanced techniques such as model compression, optimization, and compilation. We have made ONNX Runtime optimizations available through Olive so you can streamline the entire optimization process for a given hardware with simple experience.
Here is an example of Llama2 optimization with Olive, which harnesses ONNX Runtime optimizations highlighted in this blog. Distinct optimization flows cater to various requirements. For instance, you have the flexibility to choose different data types for quantization in CPU and GPU inference, based on your accuracy tolerance. Additionally, you can fine-tune your own Llama2 model with Olive-QLoRa on client GPUs and perform inference with ONNX Runtime optimizations.
Usage Example
Here is a sample notebook that shows you an end-to-end example of how you can use the above ONNX Runtime optimizations in your application.
Conclusion
The advancements discussed in this blog provide faster Llama2 inferencing with ONNX Runtime, offering exciting possibilities for AI applications and research. With improved performance and efficiency, the horizon is wide open for innovation, and we eagerly await new applications built with Llama2 and ONNX Runtime by its vibrant community of developers. Stay tuned for more updates!