QNN Execution Provider
The QNN Execution Provider for ONNX Runtime enables hardware accelerated execution on Qualcomm chipsets. It uses the Qualcomm AI Engine Direct SDK (QNN SDK) to construct a QNN graph from an ONNX model which can be executed by a supported accelerator backend library. OnnxRuntime QNN Execution Provider can be used on Android and Windows devices with Qualcomm Snapdragon SOC’s.
Contents
- Install Pre-requisites (Build from Source Only)
- Build (Android and Windows)
- Pre-built Packages (Windows Only)
- Qualcomm AI Hub
- Configuration Options
- Supported ONNX operators
- Running a model with QNN EP’s HTP backend (Python)
- QNN context binary cache feature
- Usage
- Error handling
Install Pre-requisites (Build from Source Only)
If you build QNN Execution Provider from source, you should first download the Qualcomm AI Engine Direct SDK (QNN SDK) from https://qpm.qualcomm.com/main/tools/details/qualcomm_ai_engine_direct
QNN Version Requirements
ONNX Runtime QNN Execution Provider has been built and tested with QNN 2.22.x and Qualcomm SC8280, SM8350, Snapdragon X SOC’s on Android and Windows
Build (Android and Windows)
For build instructions, please see the BUILD page.
Pre-built Packages (Windows Only)
Note: Starting version 1.18.0 , you do not need to separately download and install QNN SDK. The required QNN dependency libraries are included in the OnnxRuntime packages.
- NuGet package
- Feed for nightly packages of Microsoft.ML.OnnxRuntime.QNN can be found here
- Python package
- Requirements:
- Windows ARM64 (for inferencing on local device with Qualcomm NPU)
- Windows X64 (for quantizing models. see Generating a quantized model)
- Python 3.11.x
- Numpy 1.25.2 or >= 1.26.4
- Install:
pip install onnxruntime-qnn - Install nightly package
python -m pip install -i https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/ORT-Nightly/pypi/simple/ort-nightly-qnn
- Requirements:
Qualcomm AI Hub
Qualcomm AI Hub can be used to optimize and run models on Qualcomm hosted devices. OnnxRuntime QNN Execution Provider is a supported runtime in Qualcomm AI Hub
Configuration Options
The QNN Execution Provider supports a number of configuration options. These provider options are specified as key-value string pairs.
"backend_path" | Description |
|---|---|
| ‘libQnnCpu.so’ or ‘QnnCpu.dll’ | Enable CPU backend. Useful for integration testing. CPU backend is a reference implementation of QNN operators |
| ‘libQnnHtp.so’ or ‘QnnHtp.dll’ | Enable HTP backend. Offloads compute to NPU. |
"profiling_level" | Description |
|---|---|
| ‘off’ | |
| ‘basic’ | |
| ‘detailed’ |
"profiling_file_path" | Description |
|---|---|
| ‘your_qnn_profile_path.csv’ | Specify the csv file path to dump the QNN profiling events |
See profiling-tools for more info on profiling
Alternatively to setting profiling_level at compile time, profiling can be enabled dynamically with ETW (Windows). See tracing for more details
"rpc_control_latency" | Description |
|---|---|
| microseconds (string) | allows client to set up RPC control latency in microseconds |
"vtcm_mb" | Description |
|---|---|
| size in MB (string) | QNN VTCM size in MB, defaults to 0 (not set) |
"htp_performance_mode" | Description |
|---|---|
| ‘burst’ | |
| ‘balanced’ | |
| ‘default’ | |
| ‘high_performance’ | |
| ‘high_power_saver’ | |
| ‘low_balanced’ | |
| ‘low_power_saver’ | |
| ‘power_saver’ | |
| ‘sustained_high_performance’ |
"qnn_saver_path" | Description |
|---|---|
| filpath to ‘QnnSaver.dll’ or ‘libQnnSaver.so’ | File path to the QNN Saver backend library. Dumps QNN API calls to disk for replay/debugging. |
"qnn_context_priority" | Description |
|---|---|
| ‘low’ | |
| ‘normal’ | default. |
| ‘normal_high’ | |
| ‘high’ |
"htp_graph_finalization_optimization_mode" | Description |
|---|---|
| ‘0’ | default. |
| ‘1’ | faster preparation time, less optimal graph. |
| ‘2’ | longer preparation time, more optimal graph. |
| ‘3’ | longest preparation time, most likely even more optimal graph. |
"soc_model" | Description |
|---|---|
| Model number (string) | The SoC model number. Refer to the QNN SDK documentation for valid values. Defaults to “0” (unknown). |
"htp_arch" | Description |
|---|---|
| Hardware Architecture | HTP Architecture number. Refer to the QNN SDK documentation for valid values. Default (none) |
"device_id" | Description |
|---|---|
| Device ID (string) | The ID of the device to use when setting htp_arch. Defaults to “0” (for single device). |
"enable_htp_fp16_precision" | Description Example |
|---|---|
| ‘0’ | default. |
| ‘1’ | Enable the float32 model to be inferenced with fp16 precision. |
Supported ONNX operators
| Operator | Notes |
|---|---|
| ai.onnx:Abs | |
| ai.onnx:Add | |
| ai.onnx:And | |
| ai.onnx:ArgMax | |
| ai.onnx:ArgMin | |
| ai.onnx:Asin | |
| ai.onnx:Atan | |
| ai.onnx:AveragePool | |
| ai.onnx:BatchNormalization | fp16 supported since 1.18.0 |
| ai.onnx:Cast | |
| ai.onnx:Clip | fp16 supported since 1.18.0 |
| ai.onnx:Concat | |
| ai.onnx:Conv | 3d supported since 1.18.0 |
| ai.onnx:ConvTranspose | 3d supported since 1.18.0 |
| ai.onnx:Cos | |
| ai.onnx:DepthToSpace | |
| ai.onnx:DequantizeLinear | |
| ai.onnx:Div | |
| ai.onnx:Elu | |
| ai.onnx:Equal | |
| ai.onnx:Exp | |
| ai.onnx:Expand | |
| ai.onnx:Flatten | |
| ai.onnx:Floor | |
| ai.onnx:Gather | Only supports positive indices |
| ai.onnx:Gelu | |
| ai.onnx:Gemm | |
| ai.onnx:GlobalAveragePool | |
| ai.onnx:Greater | |
| ai.onnx:GreaterOrEqual | |
| ai.onnx:GridSample | |
| ai.onnx:HardSwish | |
| ai.onnx:InstanceNormalization | |
| ai.onnx:LRN | |
| ai.onnx:LayerNormalization | |
| ai.onnx:LeakyRelu | |
| ai.onnx:Less | |
| ai.onnx:LessOrEqual | |
| ai.onnx:Log | |
| ai.onnx:LogSoftmax | |
| ai.onnx:LpNormalization | p == 2 |
| ai.onnx:MatMul | Supported input data types on HTP backend: (uint8, uint8), (uint8, uint16), (uint16, uint8) |
| ai.onnx:Max | |
| ai.onnx:MaxPool | |
| ai.onnx:Min | |
| ai.onnx:Mul | |
| ai.onnx:Neg | |
| ai.onnx:Not | |
| ai.onnx:Or | |
| ai.onnx:Prelu | fp16, int32 supported since 1.18.0 |
| ai.onnx:Pad | |
| ai.onnx:Pow | |
| ai.onnx:QuantizeLinear | |
| ai.onnx:ReduceMax | |
| ai.onnx:ReduceMean | |
| ai.onnx:ReduceMin | |
| ai.onnx:ReduceProd | |
| ai.onnx:ReduceSum | |
| ai.onnx:Relu | |
| ai.onnx:Resize | |
| ai.onnx:Round | |
| ai.onnx:Sigmoid | |
| ai.onnx:Sign | |
| ai.onnx:Sin | |
| ai.onnx:Slice | |
| ai.onnx:Softmax | |
| ai.onnx:SpaceToDepth | |
| ai.onnx:Split | |
| ai.onnx:Sqrt | |
| ai.onnx:Squeeze | |
| ai.onnx:Sub | |
| ai.onnx:Tanh | |
| ai.onnx:Tile | |
| ai.onnx:TopK | |
| ai.onnx:Transpose | |
| ai.onnx:Unsqueeze | |
| ai.onnx:Where | |
| com.microsoft:DequantizeLinear | Provides 16-bit integer dequantization support |
| com.microsoft:Gelu | |
| com.microsoft:QuantizeLinear | Provides 16-bit integer quantization support |
Supported data types vary by operator and QNN backend. Refer to the QNN SDK documentation for more information.
Running a model with QNN EP’s HTP backend (Python)
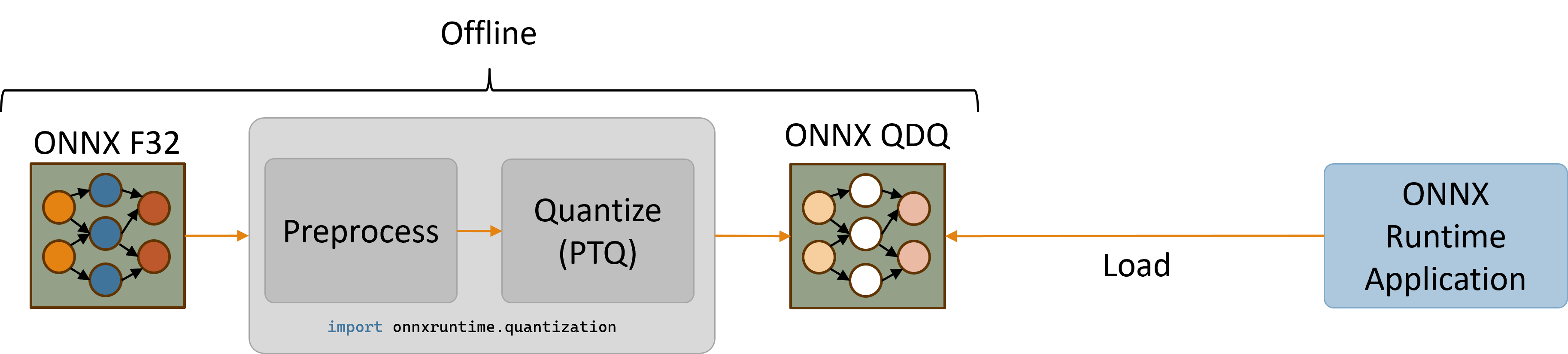
The QNN HTP backend only supports quantized models. Models with 32-bit floating-point activations and weights must first be quantized to use a lower integer precision (e.g., 8-bit or 16-bit integers).
This section provides instructions for quantizing a model and then running the quantized model on QNN EP’s HTP backend using Python APIs. Please refer to the quantization page for a broader overview of quantization concepts.
Model requirements
QNN EP does not support models with dynamic shapes (e.g., a dynamic batch size). Dynamic shapes must be fixed to a specific value. Refer to the documentation for making dynamic input shapes fixed for more information.
Additionally, QNN EP supports a subset of ONNX operators (e.g., Loops and Ifs are not supported). Refer to the list of supported ONNX operators.
Generating a quantized model (x64 only)
The ONNX Runtime python package provides utilities for quantizing ONNX models via the onnxruntime.quantization import. The quantization utilities are currently only supported on x86_64 due to issues installing the onnx package on ARM64. Therefore, it is recommended to either use an x64 machine to quantize models or, alternatively, use a separate x64 python installation on Windows ARM64 machines.
Install the ONNX Runtime x64 python package. (please note, you must use x64 package for quantizing the model. use the arm64 package for inferencing and utilizing the HTP/NPU)
python -m pip install onnxruntime-qnn
Quantization for QNN EP requires the use of calibration input data. Using a calibration dataset that is representative of typical model inputs is crucial in generating an accurate quantized model.
The following snippet defines a sample DataReader class that generates random float32 input data. Note that using random input data will most likely produce an inaccurate quantized model. Refer to the implementation of a Resnet data reader for one example of how to create a CalibrationDataReader that provides input from image files on disk.
# data_reader.py
import numpy as np
import onnxruntime
from onnxruntime.quantization import CalibrationDataReader
class DataReader(CalibrationDataReader):
def __init__(self, model_path: str):
self.enum_data = None
# Use inference session to get input shape.
session = onnxruntime.InferenceSession(model_path, providers=['CPUExecutionProvider'])
inputs = session.get_inputs()
self.data_list = []
# Generate 10 random float32 inputs
# TODO: Load valid calibration input data for your model
for _ in range(10):
input_data = {inp.name : np.random.random(inp.shape).astype(np.float32) for inp in inputs}
self.data_list.append(input_data)
self.datasize = len(self.data_list)
def get_next(self):
if self.enum_data is None:
self.enum_data = iter(
self.data_list
)
return next(self.enum_data, None)
def rewind(self):
self.enum_data = None
The following snippet pre-processes the original model and then quantizes the pre-processed model to use uint16 activations and uint8 weights. Although the quantization utilities expose the uint8, int8, uint16, and int16 quantization data types, QNN operators typically support the uint8 and uint16 data types. Refer to the QNN SDK operator documentation for the data type requirements of each QNN operator.
# quantize_model.py
import data_reader
import numpy as np
import onnx
from onnxruntime.quantization import QuantType, quantize
from onnxruntime.quantization.execution_providers.qnn import get_qnn_qdq_config, qnn_preprocess_model
if __name__ == "__main__":
input_model_path = "model.onnx" # TODO: Replace with your actual model
output_model_path = "model.qdq.onnx" # Name of final quantized model
my_data_reader = data_reader.DataReader(input_model_path)
# Pre-process the original float32 model.
preproc_model_path = "model.preproc.onnx"
model_changed = qnn_preprocess_model(input_model_path, preproc_model_path)
model_to_quantize = preproc_model_path if model_changed else input_model_path
# Generate a suitable quantization configuration for this model.
# Note that we're choosing to use uint16 activations and uint8 weights.
qnn_config = get_qnn_qdq_config(model_to_quantize,
my_data_reader,
activation_type=QuantType.QUInt16, # uint16 activations
weight_type=QuantType.QUInt8) # uint8 weights
# Quantize the model.
quantize(model_to_quantize, output_model_path, qnn_config)
Running python quantize_model.py will generate a quantized model called model.qdq.onnx that can be run on Windows ARM64 devices via ONNX Runtime’s QNN EP.
Refer to the following pages for more information on usage of the quantization utilities:
- Quantization example for mobilenet on CPU EP
- quantization/execution_providers/qnn/preprocess.py
- quantization/execution_providers/qnn/quant_config.py
Running a quantized model on Windows ARM64 (onnxruntime-qnn version >= 1.18.0)
Install the ONNX Runtime ARM64 python package for QNN EP (requires Python 3.11.x and Numpy 1.25.2 or >= 1.26.4):
python -m pip install onnxruntime-qnn
The following Python snippet creates an ONNX Runtime session with QNN EP and runs the quantized model model.qdq.onnx on the HTP backend.
# run_qdq_model.py
import onnxruntime
import numpy as np
options = onnxruntime.SessionOptions()
# (Optional) Enable configuration that raises an exception if the model can't be
# run entirely on the QNN HTP backend.
options.add_session_config_entry("session.disable_cpu_ep_fallback", "1")
# Create an ONNX Runtime session.
# TODO: Provide the path to your ONNX model
session = onnxruntime.InferenceSession("model.qdq.onnx",
sess_options=options,
providers=["QNNExecutionProvider"],
provider_options=[{"backend_path": "QnnHtp.dll"}]) # Provide path to Htp dll in QNN SDK
# Run the model with your input.
# TODO: Use numpy to load your actual input from a file or generate random input.
input0 = np.ones((1,3,224,224), dtype=np.float32)
result = session.run(None, {"input": input0})
# Print output.
print(result)
Running python run_qdq_model.py will execute the quantized model.qdq.onnx model on the QNN HTP backend.
Notice that the session has been optionally configured to raise an exception if the entire model cannot be executed on the QNN HTP backend. This is useful for verifying that the quantized model is fully supported by QNN EP. Available session configurations include:
- session.disable_cpu_ep_fallback: Disables fallback of unsupported operators to the CPU EP.
- ep.context_enable: Enable QNN context cache feature to dump a cached version of the model in order to decrease session creation time.
The above snippet only specifies the backend_path provider option. Refer to the Configuration options section for a list of all available QNN EP provider options.
QNN context binary cache feature
There’s a QNN context which contains QNN graphs after converting, compiling, filnalizing the model. QNN can serialize the context into binary file, so that user can use it for futher inference direclty (without the QDQ model) to improve the model loading cost. The QNN Execution Provider supports a number of session options to configure this.
Dump QNN context binary
- Create session option, set “ep.context_enable” to “1” to enable QNN context dump. The key “ep.context_enable” is defined as kOrtSessionOptionEpContextEnable in onnxruntime_session_options_config_keys.h.
- Create the session with the QDQ model using session options created in step 1, and use HTP backend A Onnx model with QNN context binary will be created once the session is created/initialized. No need to run the session. The QNN context binary generation can be done on the QualComm device which has HTP using Arm64 build. It can also be done on x64 machine using x64 build (not able to run it since there’s no HTP device).
The generated Onnx model which has QNN context binary can be deployed to production/real device to run inference. This Onnx model is treated as a normal model by QNN Execution Provider. Inference code keeps same as inference with QDQ model on HTP backend.
#include "onnxruntime_session_options_config_keys.h"
// C++
Ort::SessionOptions so;
so.AddConfigEntry(kOrtSessionOptionEpContextEnable, "1");
// C
const OrtApi* g_ort = OrtGetApiBase()->GetApi(ORT_API_VERSION);
OrtSessionOptions* session_options;
CheckStatus(g_ort, g_ort->CreateSessionOptions(&session_options));
g_ort->AddSessionConfigEntry(session_options, kOrtSessionOptionEpContextEnable, "1");
# Python
import onnxruntime
options = onnxruntime.SessionOptions()
options.add_session_config_entry("ep.context_enable", "1")
Configure the context binary file path
The generated Onnx model with QNN context binary is default to [input_QDQ_model_path]_ctx.onnx in case user does not specify the path. User can to set the path in the session option with the key “ep.context_file_path”. Example code below:
// C++
so.AddConfigEntry(kOrtSessionOptionEpContextFilePath, "./model_a_ctx.onnx");
// C
g_ort->AddSessionConfigEntry(session_options, kOrtSessionOptionEpContextFilePath, "./model_a_ctx.onnx");
# Python
options.add_session_config_entry("ep.context_file_path", "./model_a_ctx.onnx")
Disable the embed mode
The QNN context binary content is embeded in the generated Onnx model by default. User can to disable it by setting “ep.context_embed_mode” to “0”. In that case, a bin file will be generated separately. The file name looks like [ctx.onnx]QNNExecutionProvider_QNN[hash_id]_x_x.bin. The name is provided by Ort and tracked in the generated Onnx model. It will cause problems if any changes to the bin file. This bin file needs to sit together with the generated Onnx file.
// C++
so.AddConfigEntry(kOrtSessionOptionEpContextEmbedMode, "0");
// C
g_ort->AddSessionConfigEntry(session_options, kOrtSessionOptionEpContextEmbedMode, "0");
# Python
options.add_session_config_entry("ep.context_embed_mode", "0")
Usage
C++
C API details are here.
Ort::Env env = Ort::Env{ORT_LOGGING_LEVEL_ERROR, "Default"};
std::unordered_map<std::string, std::string> qnn_options;
qnn_options["backend_path"] = "QnnHtp.dll";
Ort::SessionOptions session_options;
session_options.AppendExecutionProvider("QNN", qnn_options);
Ort::Session session(env, model_path, session_options);
Python
import onnxruntime as ort
# Create a session with QNN EP using HTP (NPU) backend.
sess = ort.InferenceSession(model_path, providers=['QNNExecutionProvider'], provider_options=[{'backend_path':'QnnHtp.dll'}])`
Inference example
Image classification with Mobilenetv2 in CPP using QNN Execution Provider with QNN CPU & HTP Backend
Error handling
HTP SubSystem Restart - SSR
QNN EP returns StatusCode::ENGINE_ERROR regarding QNN HTP SSR issue. Uppper level framework/application should recreate Onnxruntime session if this error detected during session run.